
Timer:生成式预训练 Transformer 是大型时间序列模型
Date:
深度学习为时间序列分析的进步做出了巨大贡献。 尽管如此,深度模型在现实世界的数据稀缺场景中仍可能遇到性能瓶颈,而由于当前基准测试中小模型的性能饱和,这种瓶颈可能被隐藏起来。 同时,大型模型通过大规模预训练在这些场景中展现了强大的威力。 随着大型语言模型的出现,取得了持续的进步,表现出前所未有的能力,例如少样本泛化性、可扩展性和任务通用性,而这些能力是小型深度模型所不具备的。 为了从头开始改变训练场景小模型的现状,本文针对大型时间序列模型(LTSM)的早期开发。 在预训练过程中,我们整理了多达 10 亿个时间点的大规模数据集,将异构时间序列统一为单序列序列 (S3) 格式,并开发面向 LTSM 的 GPT 风格架构。 为了满足不同的应用需求,我们将时间序列的预测、插补和异常检测转换为统一的生成任务。 这项研究的成果是一个时间序列转换器(Timer),它通过下一个词符预测进行生成式预训练,并适应各种下游任务,具有作为 LTSM 的有前途的功能。 代码和数据集位于:https://github.com/thuml/Large-Time-Series-Model。
1 简介
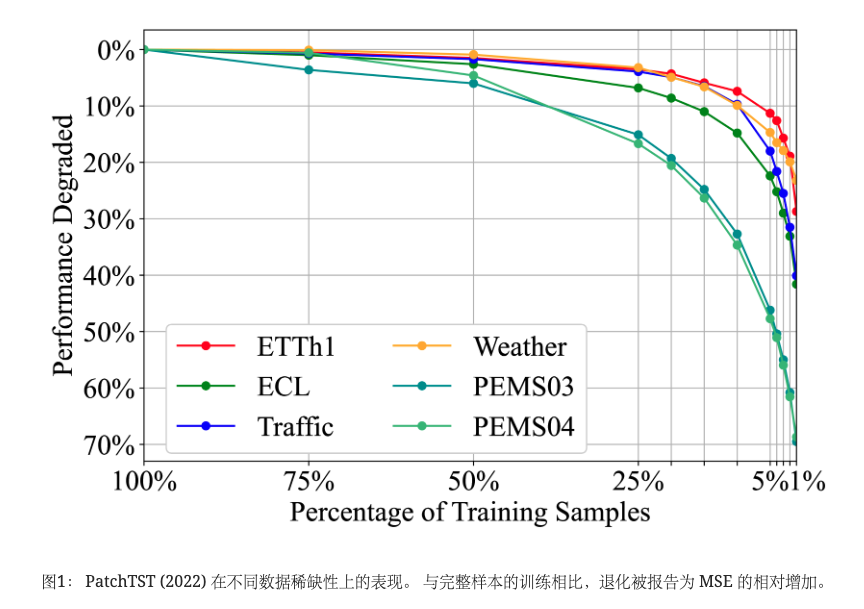
时间序列分析涵盖了广泛的关键任务,包括时间序列预测(Box等人,2015)、插补(Friedman,1962)、异常检测( Breunig 等人, 2000) 等 尽管现实世界的时间序列无处不在,但在特定应用中训练样本可能很少。 虽然深度时间序列模型取得了显着的进步(Wu 等人,2022;Zeng 等人,2023;Liu 等人,2023b),但最先进的深度模型的准确性(Nie 等人,2022) 在这种情况下仍然会急剧恶化,即使在如图 1 所示的流行基准中也是如此。 与此同时,我们正在见证大型语言模型(Radford等人,2018)的快速进展,涉及大规模文本语料库的训练,并表现出出色的少样本和零样本能力(Radford等人) ,2019)。 它可以为社区开发大型时间序列模型(LTSM)提供参考,该模型可以通过对大量时间序列数据进行预训练来在各种数据稀缺场景中进行迁移。
此外,由生成预训练(GPT)演变而来的大型模型已经展示了小型模型所不具备的多种高级能力:一个模型适合多个领域的泛化能力、一个模型应对各种场景和任务的通用性以及可扩展性性能随着参数和预训练语料库的规模而提高。 令人着迷的功能促进了通用人工智能的进步(OpenAI,2023)。 时间序列具有与自然语言相当的实用价值。 本质上,它们在生成建模(Bengio等人,2000)和自回归(Box,2013)方面表现出固有的相似性。 因此,生成式预训练大型语言模型的空前成功(Zhao等人,2023)为LTSM的进步提供了蓝图。
尽管时间序列数据的无监督预训练已被广泛探索,但基于掩码建模(Zerveas等人,2021)和对比学习(Woo等人,2022)取得了突破(Woo等人,2022) t1>,开发 LTSM 仍存在未解决的基本问题。 首先,异构时间序列的数据集基础设施和统一处理落后于其他领域。 因此,现有的无监督预训练方法通常局限于小规模,并且主要集中在数据集内传输(Zhang等人,2022;Nie等人,2022)。 其次,可扩展大型模型的架构在时间序列领域仍未得到充分探索。 据观察,在小型时间序列模型中普遍且有效的非自回归结构可能不适合 LTSM。 第三,现有的大规模预训练模型(Woo等人,2023;Das等人,2023b)主要集中在单一任务(例如预测)上,几乎没有解决任务统一问题。 因此,LTSM 的适用性仍然可以提高。
在本文中,我们深入研究了大型时间序列模型的预训练和适应。 通过聚合公开可用的时间序列数据集并遵循精选的数据处理,我们构建了分层容量的统一时间序列数据集(UTSD),以促进对 LTSM 可扩展性的研究。 为了在异构时间序列数据上预训练大型模型,我们提出了单序列序列(S3)格式,将具有保留模式的多元序列转换为统一的词符序列。 为了更好的泛化性和通用性,我们采用 GPT 风格的目标来预测下一个词符 (Bengio 等人, 2000)。 最终,我们提出了Timer,一个大规模预训练的Time系列Transformermer。 与流行的仅编码器架构(Nie 等人,2022;Wu 等人,2022;Das 等人,2023a)不同,Timer 表现出与大型语言模型类似的特征,例如灵活的上下文长度和自回归生成。 它还提供了显着的少样本泛化性、可扩展性和任务通用性,在预测、插补和异常检测方面优于最先进的特定任务模型。 总的来说,我们的贡献可以总结如下:
我们深入研究了 LTSM 的开发,整理了由 1B 个时间点组成的大规模数据集,提出了一种统一的序列格式来应对数据异构性,并提出了 Timer(一种用于一般时间序列分析的生成式预训练 Transformer)。
我们将 Timer 应用于各种任务,这是通过我们的统一生成方法实现的。 Timer 在每项任务中都表现出了显着的可行性和泛化性,用很少的样本就实现了最先进的性能。
通过对增加的可用时间序列数据进行预训练,Timer 展现了零样本预测能力。 在并发的大型时间序列模型之间提供定量评估和质量评估。
2 相关工作
2.1序列的无监督预训练
对大规模数据进行无监督预训练是下游应用模态理解的关键步骤,在序列方面取得了实质性成功,涵盖自然语言(Radford等人,2021)、patch级图像(包等人,2021)和视频(颜等人,2021)。 在序列建模的强大骨干(Vaswani 等人, 2017)的支持下,序列无监督预训练的范式近年来得到了广泛的研究,可分为掩蔽建模 (Devlin 等人, 2018)、对比学习(Chen 等人, 2020)、生成预训练(Radford 等人, 2018)。
受相关领域取得的重大进展的启发,时间序列的掩模建模和对比学习已经得到了很好的发展。 TST (Zerveas 等人, 2021) 和 PatchTST (Nie 等人, 2022) 采用 BERT 式的掩模预训练分别重建多个时间点和 patch。 LaST (Wang 等人, 2022b)提出基于变分推理来学习分解时间序列的表示。 对比学习也很好地融入了之前的作品(Woo等人,2022;Yue等人,2022)。 TF-C (Zhang 等人, 2022)通过时间变化和频谱来约束时频一致性。 SimMTM (Dong 等人, 2023) 将掩模建模和时间序列邻域内的对比方法结合起来。
然而,生成式预训练在时间序列领域受到的关注相对较少,尽管它在开发大型语言模型中得到了广泛应用(Touvron 等人,2023;OpenAI,2023)。 大多数大型语言模型都是带有 token 级监督的生成式预训练(Zhao 等人,2023),其中每个词符都是根据之前的上下文生成并独立监督的(Bengio 等人) ,2000)。 因此,它们不受特定输入和输出长度的限制,并且擅长多步生成。 此外,之前的研究(Wang等人,2022a;Dai等人,2022)已经证明,可扩展性和泛化很大程度上源于生成式预训练,它比其他预训练范例需要更多的训练数据。 因此,我们的工作旨在研究和振兴针对 LTSM 的生成式预训练,通过广泛的时间序列和对下游任务的巧妙设计的适应来促进。
2.2大型时间序列模型
具有可扩展性的预训练模型可以演变成大型基础模型(Bommasani等人,2021),其特点是增加模型容量和预训练规模来解决各种数据和任务。 大型语言模型甚至展示了上下文学习和涌现能力等高级能力(Wei等人,2022)。 目前,大型时间序列模型的研究还处于起步阶段。 现有的 LTSM 工作可以分为两类,其中一类是时间序列的大型语言模型。 FPT (Zhou 等人, 2023) 将 GPT-2 视为序列的表示提取器,分别在不同的下游任务上进行微调。 LLMTime (Chang 等人, 2023) 将时间序列编码为大语言模型的数字标记,在预测任务中展示了模型的可扩展性。 Time-LLM (Jin 等人, 2023) 研究了增强预测的提示技术,展示了大语言模型的泛化能力。 与这些方法不同,Timer 是在时间序列上进行本地预训练的,并且无需额外的模态对齐。
另一类包括大规模时间序列的预训练模型。 ForecastFPN (Dooley 等人, 2023) 经过零样本预测的合成序列训练。 CloudOps (Woo 等人, 2023) 采用 Transformer 上的屏蔽建模来进行特定领域的预测。 Lag-Llama (Rasul 等人, 2023) 是一种采用滞后作为协变量的概率单变量预测器。 PreDcT (Das 等人, 2023b) 是一个仅解码器的 Transformer,在 Google Trends 上进行了预训练,表现出显着的零样本能力。 TimeGPT-1 (Garza & Mergenthaler-Canseco,2023) 发布了第一个用于零样本预测的商业 API。 与之前的工作不同,我们的 UTSD 包含 1B 个现实世界时间点,这不是简单的聚合,而是遵循策划的数据处理。 Timer 适用于预测之外的下游任务,并且具有良好的可扩展性。 我们也是第一个针对并发 LTSM 建立零样本预测基准的人。
3 方法
受到语言和时间序列固有的顺序结构的启发,我们利用大型语言模型的进步来开发 LTSM。 在本文中,我们提倡开发时间序列的大型模型,包括(1)利用广泛的时间序列语料库,(2)对不同的时间序列数据采用标准化格式,以及(3)生成式预训练在仅解码器 Transformer 上,自回归预测下一个时间序列词符。
3.1 数据
大规模数据集对于预训练大型模型至关重要。 然而,时间序列数据集的管理可能非常具有挑战性。 尽管数据无处不在,但存在大量低质量数据,包括缺失值、不可预测性、形状变化和频率不规则,这显着影响了预训练的效果。 因此,我们建立了过滤高质量数据和堆叠时间序列语料库层次结构的标准。 具体来说,我们记录每个数据集的统计数据,包括(1)基本属性,例如时间步长、变量数、文件大小、频率等; (2)时间序列特征:周期性、平稳性、可预测性。 这也使我们能够评估不同数据集的复杂性并逐步进行可扩展的预训练。
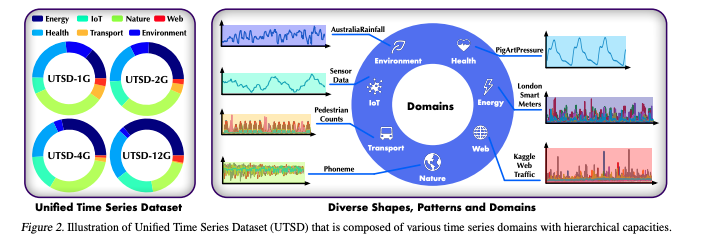
我们整理了统一时间序列数据集 (UTSD),如图 2 所示。 UTSD 采用分层能力构建,以促进大型模型的可扩展性研究。 UTSD涵盖七个领域,时间点多达10亿个(UTSD-12G),涵盖了时间序列分析的典型场景。 遵循保持模式多样性的原则,我们在每个层次中包含尽可能多样化的数据集,确保在扩展时每个域的数据大小几乎平衡,并且复杂性根据计算的统计数据逐渐增加。 我们在 https://huggingface.co/datasets/thuml/UTSD 上发布了四卷。
值得注意的是,我们使我们的管理适用于不断增加的开源数据集,这有利于时间序列语料库的不断扩展。 特别是,我们对最近的LOTSA (Woo等人,2024)进行了相同的程序,这是一项具有27B时间点的伟大努力,探索零样本预测并建立LTSM的基准。 详细的构建和统计数据在附录A中提供。
3.2 训练策略
与自然语言不同,自然语言通过完善的离散标记化和形状规则的序列结构来促进,由于序列的幅度、频率、平稳性和时间差异等异质性,构建统一的时间序列序列并不容易。不同数量、系列长度和用途的数据集。 为了促进广泛时间序列的预训练,我们建议将异构时间序列转换为单序列序列(S3),保留具有统一上下文长度的序列变化模式。
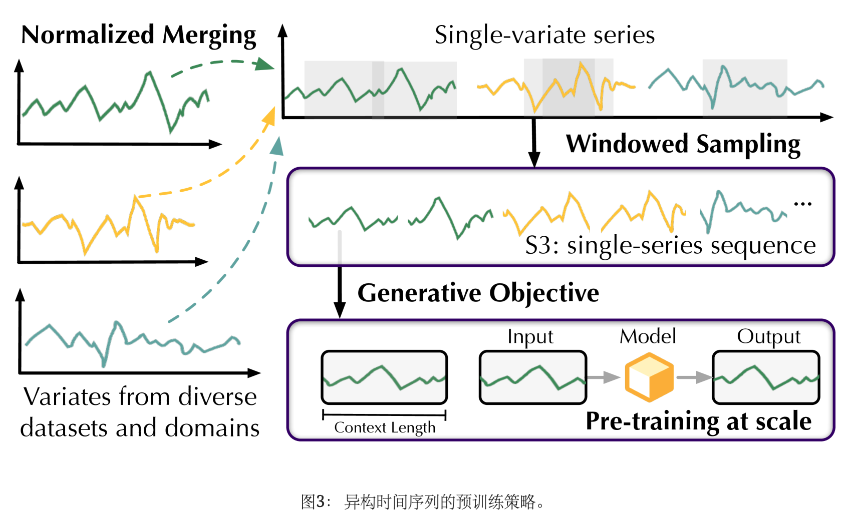
如图 3 所示,我们的初始步骤涉及在变量级别进行归一化和合并。 每个代表一个变量的系列将按照 9:1 的比例分为训练部分和验证部分进行预训练。 我们应用训练分割的统计数据来标准化整个系列。 标准化时间序列被合并到单变量序列池中。 训练的单变量序列的时间点遵循正态分布,这减轻了多个数据集之间的幅度和变量数量的差异。
我们通过窗口从池中均匀采样序列,获得具有固定上下文长度的单序列序列,如S3的格式。 所提出的格式本质上是渠道独立性 CI (Nie 等人, 2022) 的扩展。 然而,CI 需要时间对齐的多元序列,并将变量维度展平到同一批次,从而要求该批次样本源自同一数据集。 基于我们的格式,该模型观察来自不同时期和不同数据集的序列,从而增加了预训练难度并将更多注意力转移到时间变化上。 S3不需要时间对齐,适用于广泛的单变量和不规则时间序列。 然后,我们采用生成预训练,其中单系列序列被视为时间序列的标准句子。
3.3 模型设计
鉴于对大型时间序列模型主干的探索有限,我们在第 4.5 节中以相同的预训练规模广泛评估候选主干,这验证了 Transformer 是可扩展的选择。 此外,我们回顾了基于 Transformer 的时间序列预测模型,这些模型近年来经历了显着的发展。 它们可以按照类似的管道分为仅编码器和仅解码器架构。 如图4所示,流行的小型时间序列预测器(仅编码器的非自回归模型)使用回溯序列的全局扁平化表示来生成预测。 尽管直接投影可能受益于端到端监督,但扁平化也可以消除通过注意力建模的顺序依赖关系,从而削弱 Transformer 层以揭示时间变化的模式。
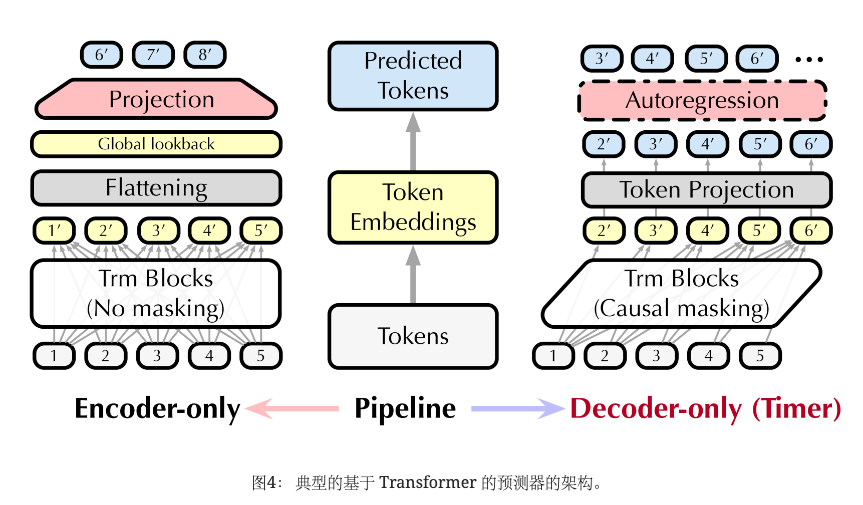
受到具有迭代生成能力的仅解码大语言模型取得的实质性进展的启发,我们选择了一种尚未充分探索的自回归方法来进行生成预训练。 由于语言模型自回归预测下一个词符:

4 实验
我们通过统一的生成方案来解决时间序列预测、插补和异常检测问题,将 Timer 展示为大型时间序列模型,如图 5 所示。 我们将 Timer 与最先进的特定任务模型进行比较,并展示在数据稀缺场景下进行预训练的好处,即大型模型的少样本能力。 此外,我们深入研究了模型的可扩展性,包括模型/数据大小,并尝试跨并发大型时间序列模型构建全面的零样本评估。 所有下游数据集都不包含在预训练阶段,以防止数据泄漏。 我们在附录B.1和B.2中提供了预训练和适应的详细实现和模型配置。
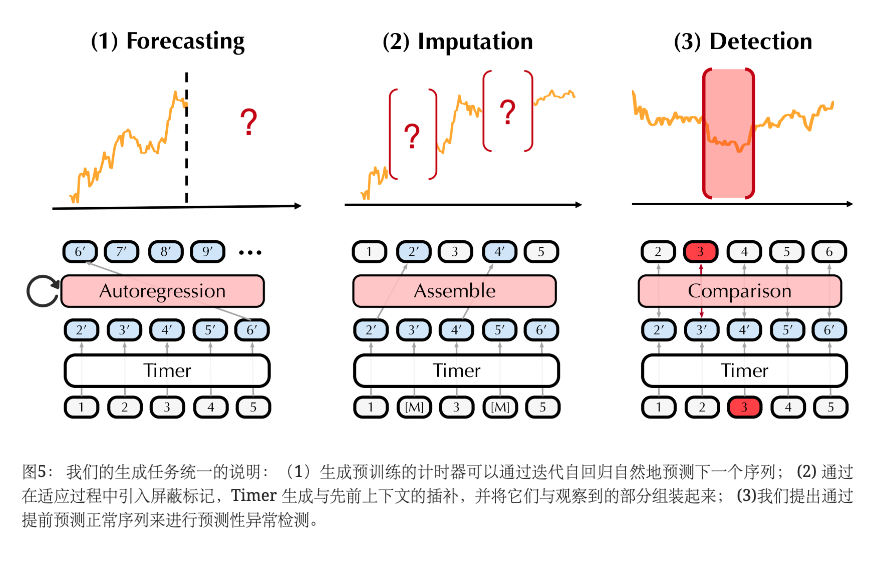
4.1时间序列预测
设置

结果
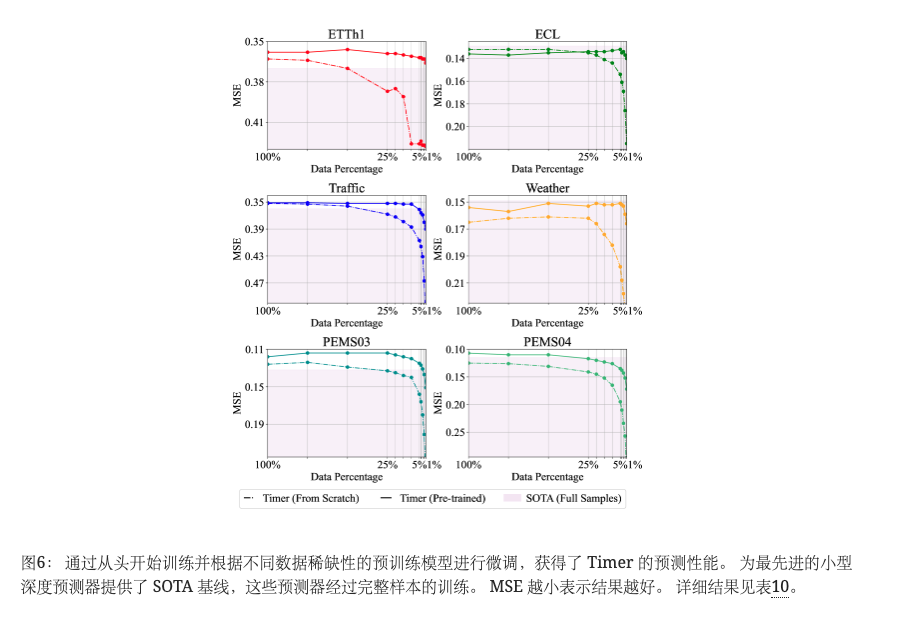
如图6所示,我们展示了不同数据稀缺性下预训练的Timer(实线)和从头训练的Timer(虚线)的结果。 我们还通过在完整样本上对最先进的预测者进行训练作为竞争基准来评估他们。 具体来说,我们在每个数据集上训练 PatchTST (Nie 等人, 2022) 和 iTransformer (Liu 等人, 2023b) 并将更好的数据集报告为 SOTA。 在少量样本上进行微调的定时器与先进的小型深度预报器相比显示出极具竞争力的结果,特别是在仅使用 ETTh1 的 1%可用样本、Traffic 的 5%可用样本、PEMS03 的 3%可用样本和 PEMS04 的 25%可用样本的情况下取得了更好的结果,并表现出非凡的能力。
为了评估预训练的好处,我们比较实线和虚线,区别在于是否加载预训练的检查点。 具体来说,在完整样本上训练随机初始化计时器的性能可以通过仅使用 ETTh1 中的 2%训练样本进行微调我们的预训练计时器来实现, 5% ECL、Weather 中的1%和 PEMS03 中的 4%,举例说明了通过 UTSD 预训练获得的可转移知识。 当所有样本都可用时,预训练定时器的性能也可以优于从头开始训练:预测误差在天气上减少为 0.165 → 0.154,在 PEMS03 上减少为 0.12 →0.118,在 0.125→ 0.107在 PEMS04 上。 总体而言,在广泛的数据稀缺场景中,可以通过 LTSM 的少样本泛化来缓解性能下降。
4.2插补
设置
插补在现实应用中无处不在,旨在根据部分观察到的数据填充损坏的时间序列。 然而,虽然各种机器学习算法和简单的线性插值可以有效地应对点级别随机发生的损坏,但现实世界的损坏通常是由于长时间的显示器关闭造成的,并且需要连续的恢复期。 因此,当试图恢复包含复杂序列变化的时间点跨度时,插补可能非常具有挑战性。 在此任务中,我们进行分段级别插补。 每个时间序列被分为 8段,每个段的长度为24,并且有被完全屏蔽的可能性。 我们通过分段长度S=24和词符编号N=15的生成预训练获得UTSD-4G上的Timer。 对于下游适应,我们在 T5 (Raffel 等人,2020) 中进行去噪自动编码,如附录 B.2 中详述,以生成方式恢复屏蔽跨度。
结果
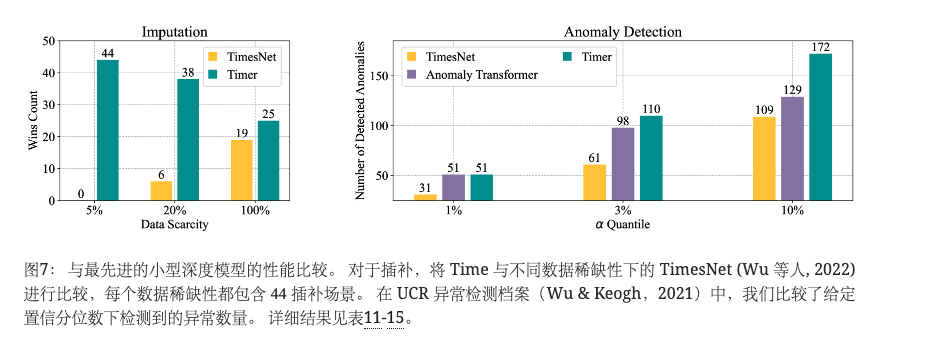
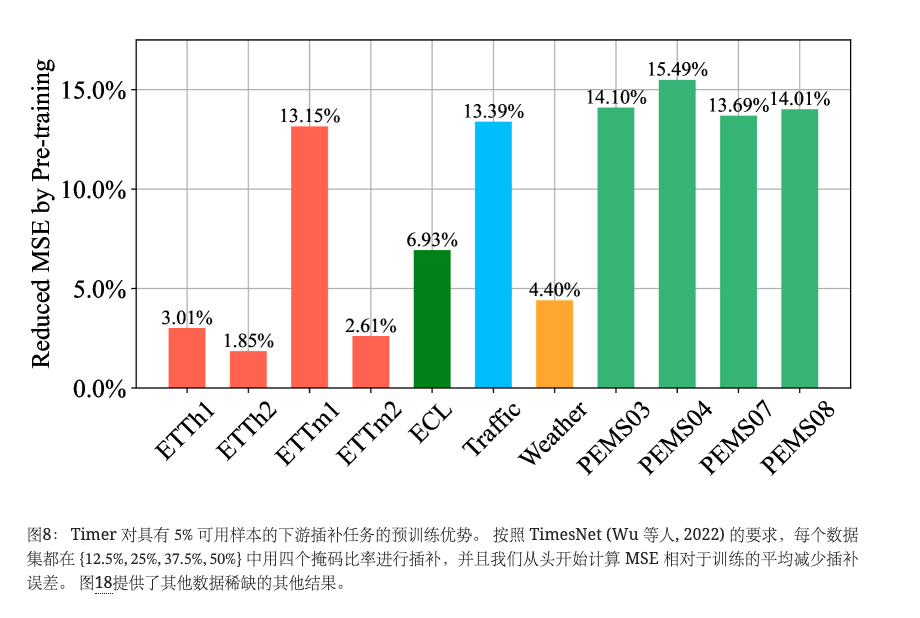
我们建立了一个全面的分段级插补基准,其中包括 11 数据集,每个数据集都有四个掩码比率。 Timer 与之前最先进的插补模型(Wu 等人,2022)进行了比较。 如图 7 左侧所示,在 的数据稀缺情况下,Timer 在 100.0% 、 86.4% 和 56.8%的 44 估算场景中的表现分别优于 {5%,20%,100%},验证了 Timer 在具有挑战性的估算任务中的有效性。 关于预训练的好处,我们将提升表示为图8中插补误差的减少率,其中预训练始终对5%下游样本产生积极影响。 图 18 中提供了对 20%和 100%可用样本的其他实验,这些实验仍然呈现出显着的性能改进。
4.3异常检测
设置
异常检测在工业和运营中至关重要。 之前的方法(Xu 等人, 2021; Wu 等人, 2022) 通常以重构方法处理无监督场景,其中训练模型来重构输入序列,并将输出视为正常系列。 基于我们的生成模型,我们以预测方法处理异常检测,该方法利用观察到的片段来预测未来的片段,并将预测的片段建立为与收到的实际值进行比较的标准。 与之前需要收集一段时间序列进行重建的方法不同,我们的预测方法允许动态进行段级异常检测。 因此,该任务被转换为下一个词符预测任务,详见附录B.2。
我们引入了包含 250 任务的 UCR 异常存档 (Wu & Keogh,2021)。 在每个任务中,为训练提供单个正常时间序列,模型应定位测试序列中异常的位置。 我们首先在训练集上训练一个预测模型,并计算预测序列和测试集上的真实数据之间的 MSE。 通过将所有分段的 MSE 视为置信水平,置信度高于 α 分位数的分段被标记为潜在的异常位置。
结果
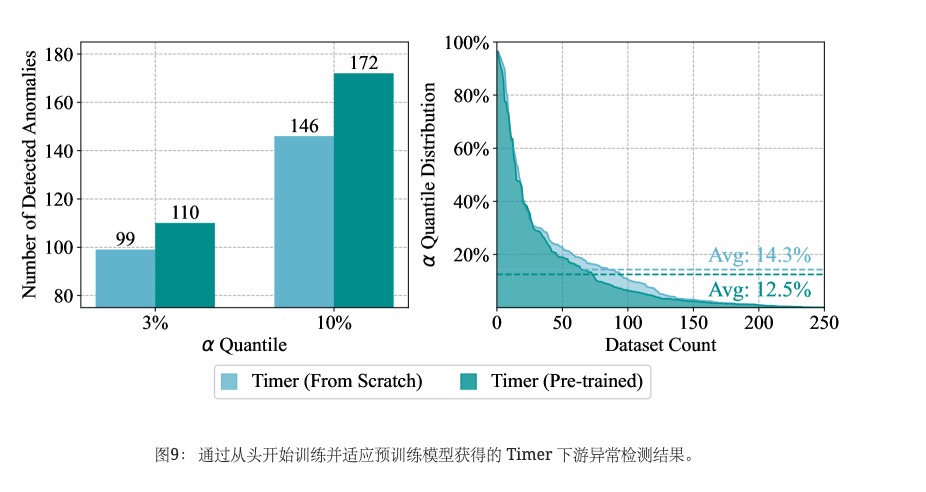
我们评估了公认的异常检测模型,包括 TimesNet (Wu 等人, 2022) 和 Anomaly Transformer (Xu 等人, 2021)。 如图7右侧所示,我们展示了给定分位数检测到的异常数量,其中 Timer 优于其他高级异常检测模型,展示了我们的生成时间序列模型的多功能性。 此外,图9使用两个指标比较了预训练模型和从头开始训练的模型的检测性能。 左图为 3% 和 10%分位数内模型已完成检测的数据集数量,右图为所有250UCR 数据集,其中具有较小平均分位数的预训练计时器可作为更准确的检测器。
4.4可扩展性
可扩展性是从预训练模型到大型模型的基本属性。 为了研究 Timer 的扩展行为,我们使用增加的模型大小和数据大小来预训练 Timer(如附录 B.1 中详述),并在 PEMS 所有子集的下游预测中对其进行评估。
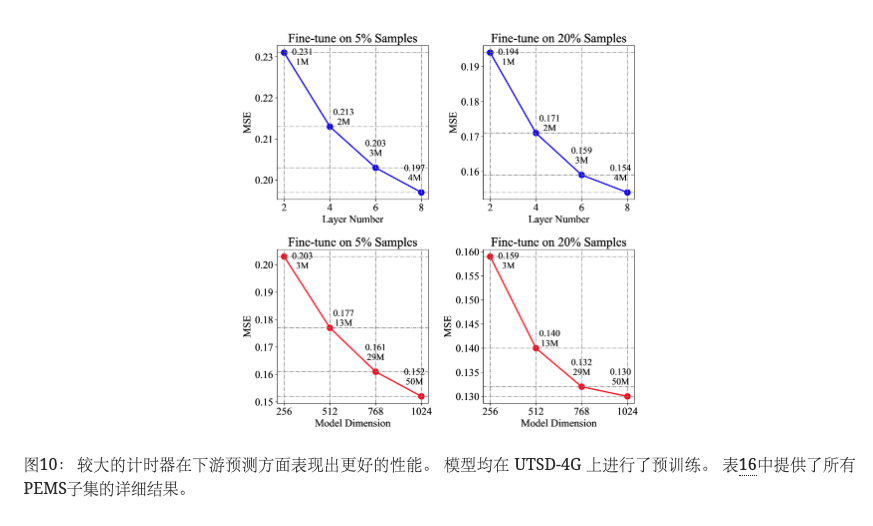
型号尺寸
我们保留 UTSD-4G 作为预训练集。 结果如图10所示。 在保持模型尺寸D=256的同时,我们增加层数。 参数从 1M 增长到 4M 导致两个少样本场景中的预测误差平均分别降低 14.7%和 20.6%。 随后,我们在固定层数L=6下增加模型维度,将参数从3M扩大到50M,使得25.1%和18.2%的性能进一步提升,验证了扩大模型尺寸的功效。
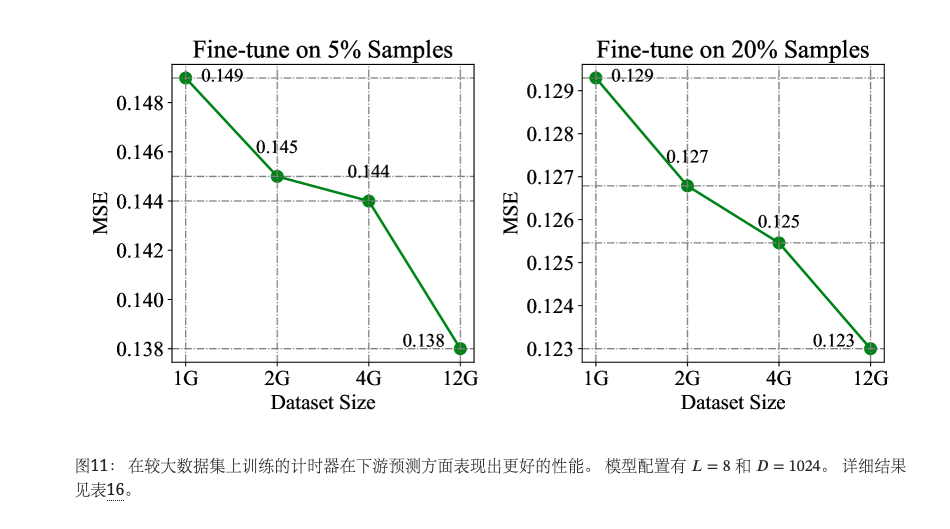
数据规模
我们在相同模型大小和不同 UTSD 大小下预训练 Timer,随着图 11 中扩大的预训练规模,表现出稳定的改进。 与之前扩大模型大小相比,好处相对较小,这可以归因于这些数据集的性能饱和。 与大型语言模型相比,Timer 的参数规模仍然可以很小,这表明时间序列模态的参数效率更高,这也得到了先前工作(Das 等人,2023b)的支持。 由于大型模型的缩放定律(Kaplan等人,2020)凸显了数据与模型参数同步缩放的重要性,因此时间序列领域的数据基础设施仍然迫切需要加速促进LTSM的发展。
总体而言,通过增加模型大小和数据规模,Timer 在少样本场景下将预测误差降低为 0.231→ 0.138(−40.3%)和 0.194→0.123(−36.6%),超越了最先进的多元预测器 (Liu 等人, 2023b) 在 PEMS 数据集的完整样本上进行训练(0.139)。
4.5模型分析
LTSM 的骨干
深度学习方法带来了时间序列分析的繁荣,提出了用于建模顺序时间序列模态的各种支柱。 为了验证大型时间序列模型的适当选项,我们将 Timer 与四个候选者进行比较:基于 MLP 的 TiDE (Das 等人, 2023a)、基于 CNN 的 TCN (Bai 等人, 2018) )、基于 RNN 的 LSTM (Hochreiter & Schmidhuber, 1997) 和仅编码器的 PatchTST (Nie 等人, 2022)。
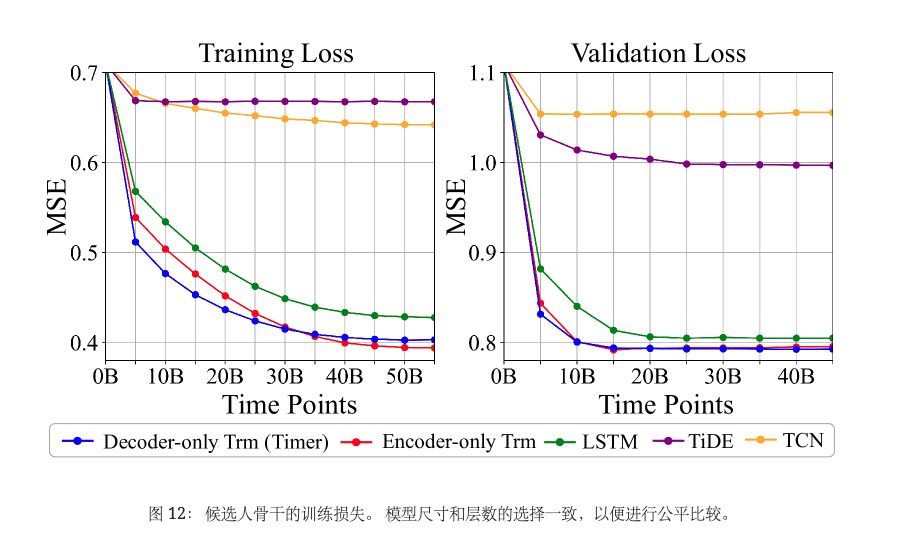
为了确保评估在不同主干上具有可比性,我们保持相同的模型配置,包括模型维度和层数,并分别在 UTSD-4G 上预训练这些主干。 我们将定时器的词符长度设置为 S=96,将上下文长度设置为672。 对于其他非自回归主干网,我们通过在 672-pred-96设置中直接多步预测来对其进行预训练。 训练和验证的损失曲线计算为同一组模型输出(长度- 96时间序列)的MSE。 如图12所示,Transformer 作为 LTSM 的骨干展现出了出色的可扩展能力,而基于 MLP 和 CNN 的架构可能会遇到容纳不同时间序列数据的瓶颈。
仅解码器与解码器 仅编码器
虽然图12中仅编码器的Transformer实现了较小的训练损失,但大型语言模型的进展表明仅解码器模型在下游适应方面可能具有更强的泛化能力(Wang等人, 2022a; Dai 等人, 2022),这是 LTSM 的本质目的。 因此,我们继续比较他们在不同程度的数据稀缺情况下的预测表现。
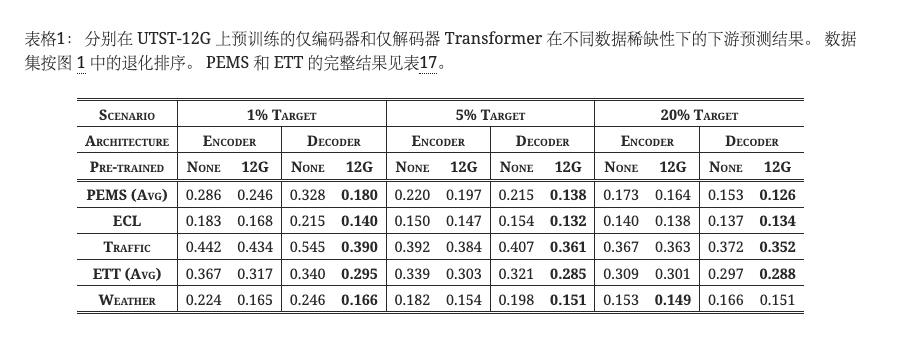
我们在表1中的六个基准上详细评估了两种架构。 在从头开始训练的情况下(预训练=无),如果训练样本不足(目标= 1%),仅编码器的Transformer将获得更好的性能。 相反,当在端到端场景中提供更多训练样本时,仅解码器架构将表现出更高的性能。 在 UTSD-12G(Pre-trained = 12G)上进行预训练后,Timer 作为仅解码器的 Transformer 在大多数下游场景中实现了最佳性能,表明比仅编码器预训练模型具有更好的泛化能力。 这些观察结果与大型语言模型中的几个发现一致,并阐明了为什么仅编码器结构在时间序列领域变得普遍。 现有的基准测试仍然很小,并且仅编码器的模型可能在端到端场景中过度拟合。 同时,仅解码器的 Transformer 擅长在不同领域进行泛化,是开发大型时间序列模型的有前途的选择。
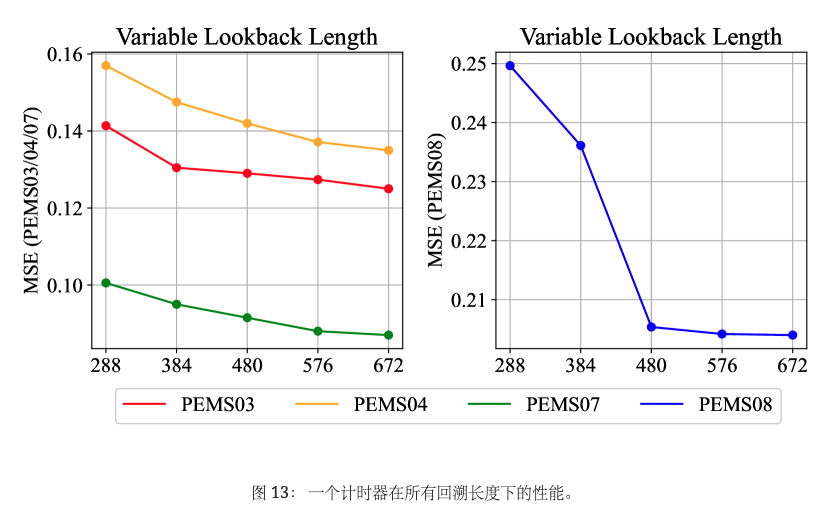
灵活的序列长度
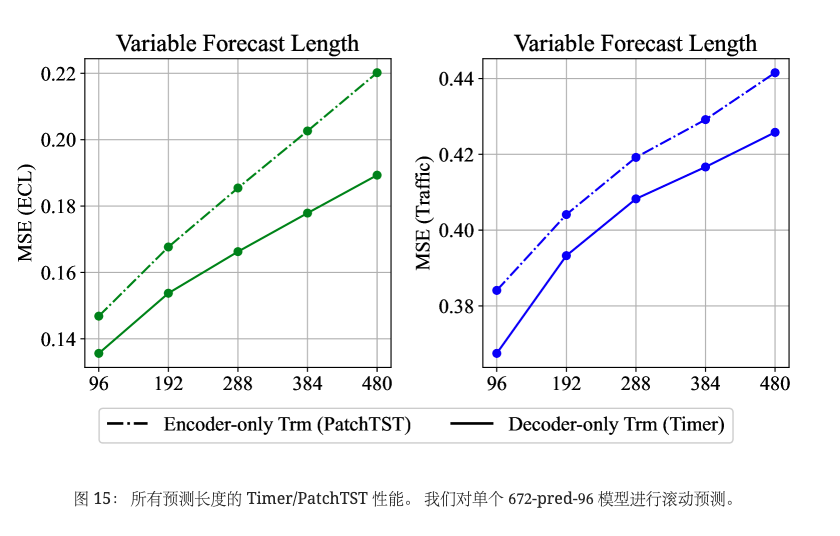
通常,当前的深度预测模型是根据特定的回溯和预测长度进行训练的,限制了其多功能性。 相反,仅解码器架构可以提供解决不同序列长度的灵活性。 例如,由于等式 4 中概述的 Token 明智监督,一个计时器适用于不同的回溯长度。 除了可行性之外,它还通过增加图13中的回溯长度来实现增强的性能。 至于预测长度,增加工作(刘等人,2024)带来了自回归(迭代多步预测)的复兴,使得能够生成任意长度的未来预测。 我们通过对图 15 中的所有预测长度滚动一个模型来探索这一范式,其中仅解码器的 Times 表现出更小的错误累积,从而实现更好的性能。
4.6 大型时间序列模型的评估
时间序列领域大型模型的开发日益增多(Garza & Mergenthaler-Canseco, 2023; Das 等人, 2023b; Woo 等人, 2024; Ansari 等人, 2024; Goswami 等人,2024)。 一个特别令人着迷的研究方向是零样本预测(ZSF),它有可能革新训练小模型或针对每个特定场景微调语言模型的传统做法。 零样本泛化代表了大型模型的复杂能力,需要大量的模型容量和对广泛数据集的预训练。 因此,我们正在积极扩展我们的数据集,通过整合该领域最新的数据基础设施(Woo等人,2024)来预训练更大规模(1B/16B/28B)的Timer。 鉴于对研究人员和从业者的重要价值,我们广泛评估了并发大型模型,并建立了第一个 LTSM 零样本预测基准,详见附录 B.2
质量评估
我们的评估评估了表9中LTSM的质量,包括(1)基本属性,例如预训练规模、参数; (2)适用任务、上下文长度等能力。当前的LTSM本质上是基于Transformer构建的,与大语言模型相比,参数数量明显较少。 仍有潜力支持更多任务和更长的上下文。
定量评价
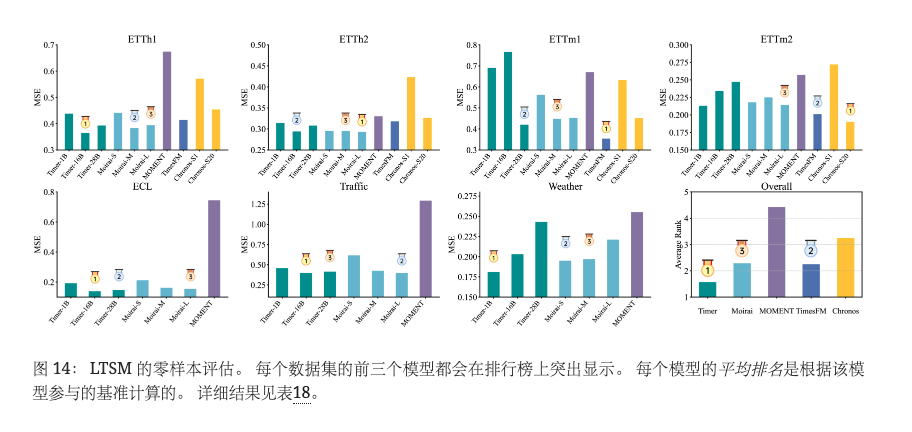
我们对预训练期间未出现的七个数据集应用官方检查点。 使用 MSE 通过预测每个数据集中所有窗口的未来 96点来公平评估性能。 图 14 展示了每个模型的结果和排名,其中排名靠前的 LTSM 是 Timer、Moiria (Woo 等人, 2024) 和 TimesFM (Das等人,2023b)。 然而,性能和预训练规模之间的正相关性仍然相对较弱,凸显了高质量数据以及数据和模型大小同步缩放的重要性。
5 结论和未来工作
现实世界的时间序列分析越来越强调对大型时间序列模型 (LTSM) 的需求。 在本文中,我们发布了包含 10 亿个时间点的时间序列数据集,提出了一种统一的序列格式来解决多元时间序列的异构性,并开发了一个生成式预训练 Transformer 作为可泛化、可扩展、任务通用的 LTSM。 根据经验,我们在预测、插补和异常检测方面评估我们的模型,在数据稀缺的情况下产生最先进的性能和显着的预训练优势。 进一步的分析验证了模型的可扩展性,探索了 LTSM 的架构,并强调了我们自回归生成的多功能性。 通过对可用的大型模型进行零样本预测,我们对 LTSM 进行了初步的定量评估。 质量评估揭示了未来发展的关键途径,包括更好的零样本泛化以及促进概率和长上下文预测。
影响报告
本文旨在推进时间序列大型模型的开发。 在这项工作中,我们发布了用于可扩展预训练的高质量且统一的时间序列数据集,可以作为预训练和建立新基准的基础。 结果大型模型展示了显着的泛化有效性、跨各种任务的多功能性以及改进性能的可扩展性,为未来的研究和从业者的应用价值提供了宝贵的见解。 我们的论文主要以科学研究为主,没有明显的负面社会影响。