DeepSeek-R1:通过强化学习提升LLM的推理能力
Date:
背景介绍
DeepSeek-V3的横空出世引起了轰动,当o1、Claude、Gemini和Llama 3等模型还在为数亿美元的训练成本苦恼时,DeepSeek-V3用557.6万美元的预算,在2048个H800 GPU集群上仅花费3.7天/万亿tokens的训练时间,就达到了足以与它们比肩的性能。DeepSeek-V3 是一个 MoE(Mixture-of-Experts)语言模型,总参数量 671B,每个 Token 激活的参数量为 37B。为实现高效训练与推理,DeepSeek-V3 延续了 DeepSeek-V2 的 MLA(Multi-head Latent Attention)及 DeepSeekMoE 架构。此外,DeepSeek-V3 首创了无需辅助损失的负载均衡策略,还使用了多 Token 预测训练目标以增强性能。
在2025年初,DeepSeek- R1更是爆火,我们阅读了DeepSeek相关的技术报告,对一些要点进行了归纳总结。
模型架构
模型结构和超参数设置
DeepSeek-V3 的模型结构与 DeepSeek-V2 一致,依然是 MLA + DeepSeekMoE,总参数 671B,激活参数 37B。总共 61 层,Hidden 维度为 7168:
MLA:
- Attention Head 个数 nh:128
- 每个 Head 的维度 dh:128(需要说明的是,非 MLA 时,一般 nh * dh = Hidden 维度;而 MLA 中并不是这样,dh 会大于 Hidden 维度 / nh,比如这里 128 > 7168/128 = 56)
- KV 压缩维度 dc:512
- Q 压缩维度 d’c:1536
- 解耦的 Q 和 K(RoPE)的维度 dRh:64
MoE:
- 前 3 层 Transformer Layer 的 FFN 保持为 Dense 结构(1 个专家),后续 Layer 的 FFN 替换为 MoE 结构。
- MoE 中包含 1 个共享专家(Share Expert)和 256 个路由专家(Routed Expert),每个专家的 Hidden 维度为 2048。每个 Token 激活 8 个路由专家,并且确保每个 Token 最多被发送到 4 个节点。 MTP:
- MTP 的深度 D 为 1,也就是除了精确预测下一个 Token 外,每个 Token 还额外预测一个 Token。
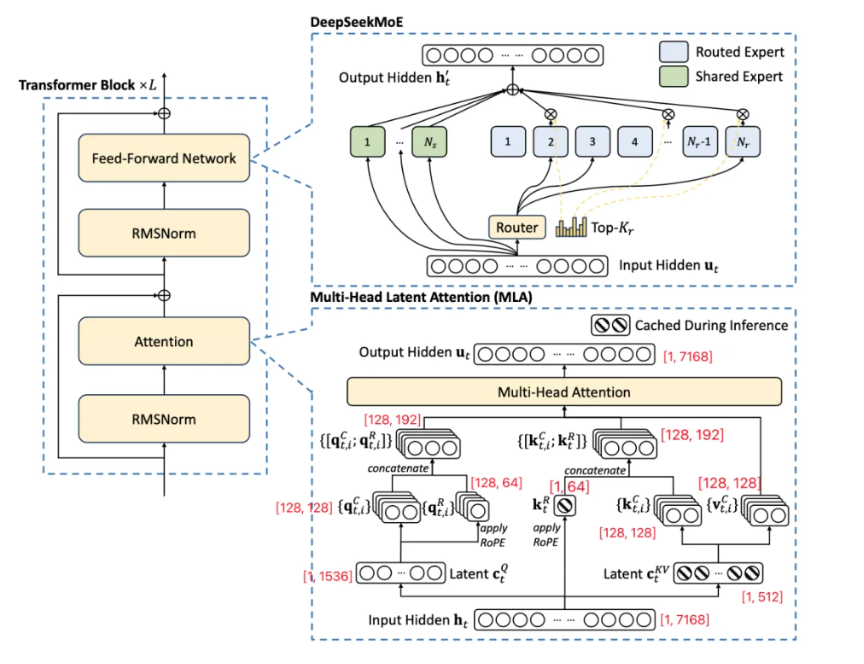
DeepSeek- MLA(Multi-head Latent Attention)
- 标准attention计算公式

记S为Softmax,展开t位置的attention计算公式,t位置的attention结果只和t位置的Q以及之前所有位置的K-V有关,如果不缓存K-V,就需要不停的重复计算K-V,缺点是缓存大量参数的KV会占用大量显存
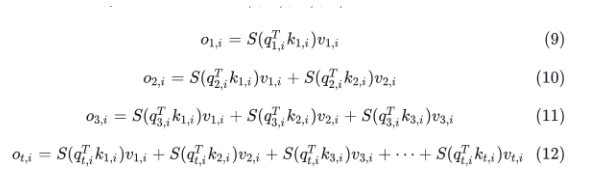
- MLA
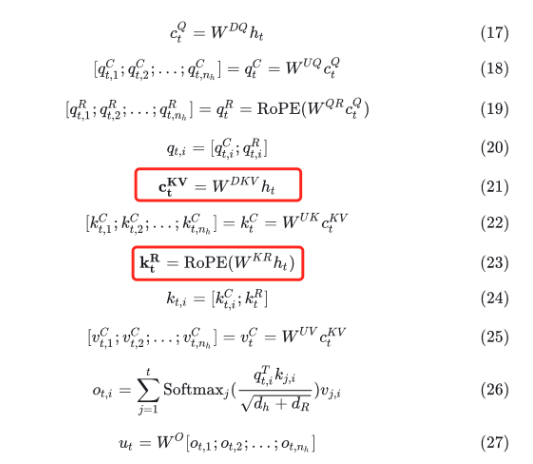
只需要缓存选中的部分,W表示升维或降维矩阵,在计算过程中,WUQ和WUK会被吸收,减少显存占用空间的同时不增加计算量,ctKV远小于直接缓存kv的消耗
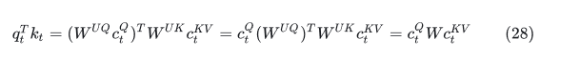
RoPE是相对位置编码,用于表示token的相对位置,但RoPE不能直接作用于公式(22)上,所以使用公式(19)和(23)解耦,使用(20)和(24)合并后计算完整的attention
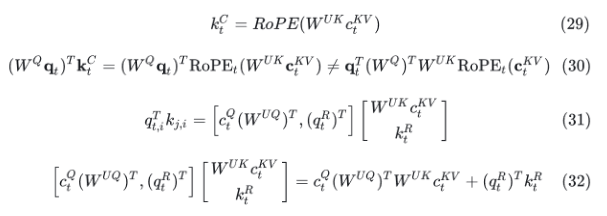
不同策略显存占用
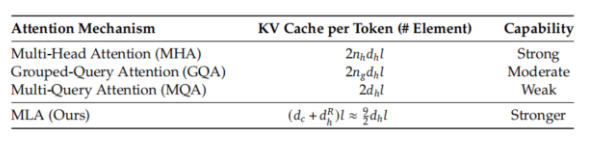
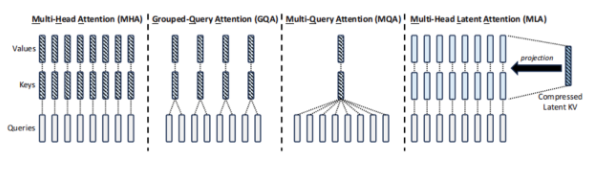
注:不同策略示意图,GQA多组Q矩阵使用一个K、V,MQA是所有的Q矩阵共用一个K、V
DeepSeek MoE(Mixture-of-Experts)
- 负载均衡策略
MOE模型由一个门控网络和多个专家网络组成,能够显著提升模型的参数量并且适合并行化计算,不同专家能够专注于处理不同类型的输入。但训练过程中,某些专家可能被过度使用,而其他专家可能被忽略,导致负载不均衡。
- 负载不均衡可能会导致模型泛化能力下降,没有被充分训练的专家网络推理的结果可能不够好;
- 门控网络可能失效,集中分配激活频次高的专家网络;
- MOE一般会采用并行策略,导致未被激活的专家网络算力闲置,频繁激活的专家网络算力紧张
- 传统辅助损失
在常规的loss中加入辅助损失,辅助损失可以定义为变异系数即重要性得分的标准差 / 均值,重要性得分为专家网络被选中的次数或者概率,通过超参数控制辅助损失的权重,辅助损作为一个独立的损失项,参与训练优化
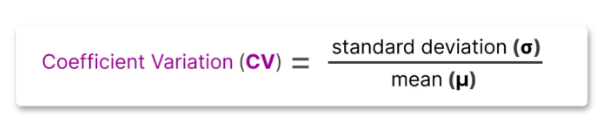
- 但加入辅助损失后会增加模型训练的复杂性,并且会影响模型优化的目标
- deepseek的无辅助损失自然均衡
1)deepseek MOE基础架构
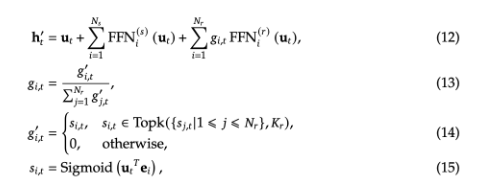
相比传统MOE架构,使用更细粒度的专家,并隔离出一些专家作为共享专家,ut表示输入的token,ht表示FFN的输出,git表示专家网络的得分,最后根据sigmoid的结果选择激活的专家网络
2)无辅助损失负载均衡
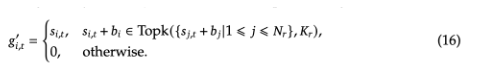
为每个专家网络的得分增加一个偏差项bi,偏差项根据每一步训练的结果更新,过载的专家网络减少γ,选中次数过少的专家网络增加γ
3)互补的序列级辅助损失
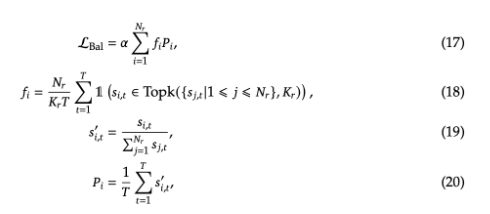
鼓励每个序列中的专家负载更加均衡,避免负载集中在少数专家上,从而提高模型的效率和公平性,T表示序列长度,Kr表示激活的专家网络数量,pi表示序列所有token选择某个网络的平均概率,当一个序列对某个专家网络的得分均过高时,即激活的网络数量少,则fi的值会变大,导致损失变大
MTP(Multi Token Prediction)
MTP 目标使训练信号更密集,提高数据效率。另一方面,MTP 能使模型能够预先规划其表示,以便更好地预测未来的token。
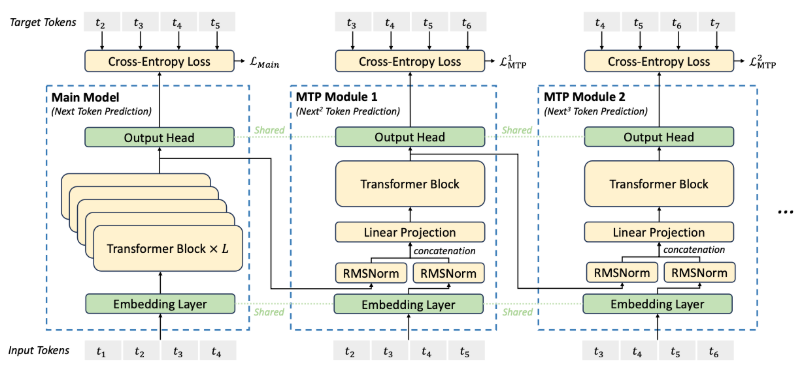
使用D个模块预测未来D个token,每个MTP模块由一个共享的Embedding层、共享的Output Head、一个transformer块和一个投影矩阵组成。对于第i个token在第k个预测深度的输入可以表示为:

经过Output Head后由softmax函数得到第k个预测token的概率

2)MTP训练目标
每个未来预测的token计算交叉熵损失
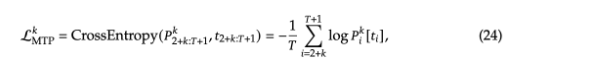
对所有交叉熵损失求均值后乘以一个权重作为大模型V3的一个目标

3)推理应用
MTP的策略是为了提高模型的性能,当前推理过程中会舍弃MTP模块。这些MTP模块也可以用来加速解码过程,如果使用MTP一次预测2个token的方式,每秒能够处理的token数提升为单token预测的1.8倍,第二个token的采纳率在85%-90%之间
大模型Infra建设
FP8混合精度训练框架
- DeepSeek-V3里引入了一种 FP8 混合精度训练框架,并首次在超大规模模型上验证了其有效性。
- DeepSeek在采用FP8格式时,采用了”混合精度”的方案。在训练时,它的大部分核心计算内核均采用 FP8 精度实现。包括前向传播、激活反向传播和 权重反向传播都用了 FP8 作为输入,并输出 BF16 或 FP32 格式的结果。这一设计理论上使计算速度相较于原始的 BF16 方法提升了一倍。此外,DeepSeek中的向量激活值以 FP8 格式存储,供反向传播使用,从而显著降低了内存消耗。
- 针对某些对低精度计算敏感算子和一些低成本算子,比如Embedding模块、输出头、MoE 门控模块、归一化算子以及attention算子保留了FP16乃至FP32的精度。这样能保证数据的精确性。同时为了保证数值稳定性,DeepSeek还将主权重、权重梯度和优化器状态以更高精度存储。
- 细粒度量化,提升累加精度
使用FP8精度计算的部分速度提升一倍,模型最终的精度损失为0.25%
DualPipe高效流水线并行算法
- 朴素流水线并行
将模型按照层间切分成多个部分(Stage),并将每个部分(Stage)分配给一个 GPU。然后,对小批量数据进行常规的训练,在模型切分成多个部分的边界处进行通信
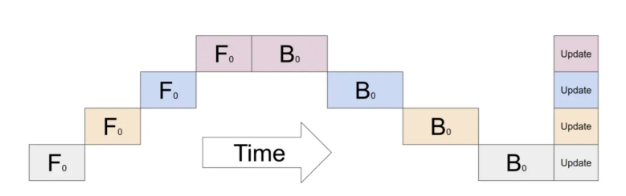
该方案在任意给定时刻,除了一个 GPU 之外的其他所有 GPU 都是空闲的,这些空闲的时间被称为bubble。因此,如果使用 4 个 GPU,则几乎等同于将单个 GPU 的内存量增加四倍,而其他资源 (如计算) 相当于没用上,朴素流水线存在很多的Bubble,并且算上通信的开销,这一方案的效率是很低下的。
bubble time:O(K-1 / K) ,K为GPU数量,数量越大bubble的时间越接近1
micro-batch并行(谷歌GPipe)
将一个batch的数据拆分为更小的micro batch,这样不同的gpu就可以在同一时间参与计算,bubble的时间相比朴素流水线大幅降低
bubble time: O(K-1 / M+K-1),当M>=4K时,bubble产生的时间对最终训练的时间可以忽略不计
缺点:需要缓存多个micro batch的中间变量和梯度
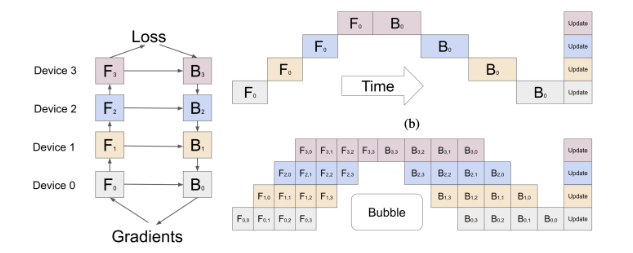
1F1B(微软 PipeDream)
forward和backward交替进行,在计算F41-B41之后可以释放中间变量占用的显存,计算F42时可复用这部分显存。采用轮询的调度方式,保证同一个batch的前向计算和后向计算在同一个卡上

bubble time:O(K-1 / M+K-1),与micro-batch是一样的,但峰值显存可以降低37.5%,这样就能通过增加micro-batch的值间接降低bubble的空闲时间
缺点:根据流水线深度需要保存多套权重
ZB1P (Sea AI Lab)
将backward计算拆为两部分,分别为中间结果和模型参数计算梯度,同一批次的F和B的计算仍保持依赖,而W可在B之后的任意位置灵活调度
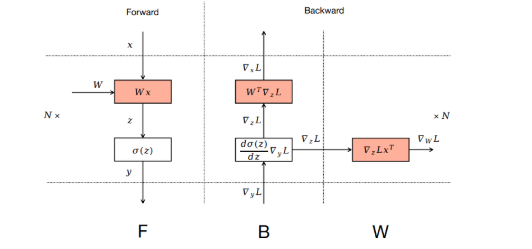
以1F1B的策略执行,首先进行一轮预热,在这个阶段,每个节点进行不同数量的前向传递。在预热阶段之后,每个工作节点进入稳定状态,它们交替执行一次前向传递和一次后向传递,以确保各个阶段之间的工作负载均衡。在最后阶段,每个工作节点处理尚未完成的微批次的后向传递,完成整个批次的处理。

进一步的优化是通过策略性的方式放置W来填充bubble的空闲时间

bubble time: 理论上可为0

缺点:显存占用为1F1B的2倍
DualPipe (DeepSeek)
通过双向输入减少bubble时间,对于backward的计算借鉴了zero bubble的策略,拆分中间结果和模型参数。在GPU计算某个批次的数据时,另一个批次的数据同步通信,这样就使计算和通信的时间重叠,在整体的训练上减少耗时

bubble time:

测试结果,减少50%的bubble时间,减少20%的通信开销
Post-Training
GRPO(Group Relative Policy Optimization)
GRPO通过优化PPO算法,移除了价值模型,降低了计算开销,同时利用群体相对优势函数和KL散度惩罚,确保策略更新既高效又稳定
Post-training阶段,丢弃掉critic model,采样一个group的回答,然后计算这个group中每个样本的reward,每个样本的Advantage就等于Reward减去均值再除标准差

DeepSeek-R1
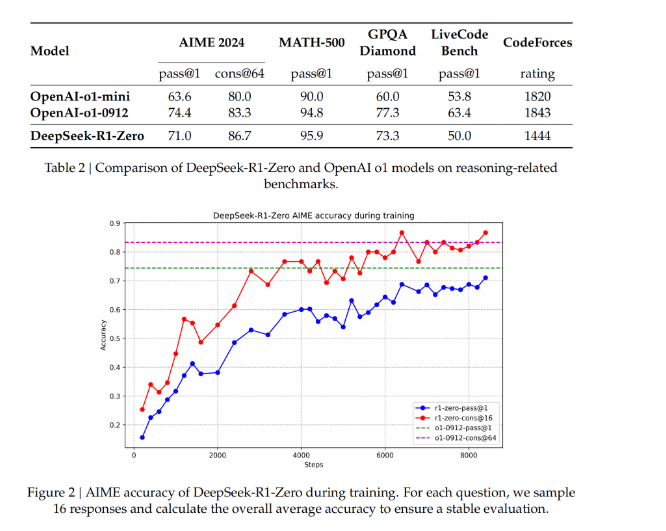
DeepSeek-R1-Zero
在没有任何监督数据的情况下,通过纯强化学习过程实现模型自我进化的能力,在V3的基础上,使用GRPO训练出了DeepSeek-R1-Zero,奖励的设置如下:
- 准确性奖励:准确性奖励模型评估响应是否正确。例如,在具有确定性结果的数学问题中,模型需要以指定格式(如框内)提供最终答案,从而能够通过规则可靠地验证正确性。类似地,对于LeetCode问题,可以使用编译器根据预定义的测试用例生成反馈
- 格式奖励:除了准确性奖励模型外,还采用了格式奖励模型,强制模型将其思考过程放在“
”和“ ”标签之间 - 没有使用基于结果或过程的神经网络奖励模型,因为发现神经奖励模型在大规模强化学习过程中可能会受到奖励欺骗的影响,并且重新训练奖励模型需要额外的训练资源,同时会使整个训练流程复杂化
推理能力得到了提升,但存在可读性差和语言混合的问题
Cold Start
构建并收集了少量长思维链数据,用于纯强化学习的初始模型。为了收集这些数据,作者探索了多种方法:使用带有长思维链示例的few-shot提示词,直接提示模型生成包含反思和验证的详细答案,收集DeepSeek-R1-Zero的可读格式输出,并通过人工注释
可读性: DeepSeek-R1-Zero存在可读性差、回答可能混合多种语言、或缺乏用于突出答案的Markdown格式的问题。作者设计了一种可读的模式,包括在每条回答的末尾添加总结,并过滤掉不便于阅读的回答。将输出格式定义为 |special_token|<推理过程>|special_token|<总结>,其中推理过程是查询的思维链(CoT),而总结用于概括推理结果。 **潜力:** 通过精心设计结合人类先验知识的冷启动数据模式,作者观察到其性能优于DeepSeek-R1-Zero。
面向推理的强化学习
在基于冷启动数据微调DeepSeek-V3-Base后,作者采用了与DeepSeek-R1-Zero相同的大规模强化学习训练流程。这一阶段的重点是增强模型的推理能力,尤其是在编码、数学、科学和逻辑推理等推理密集型任务中,这些任务通常涉及定义明确且具有清晰解决方案的问题。在训练过程中,作者观察到思维链经常出现语言混杂现象,尤其是在强化学习提示涉及多种语言时。为了缓解语言混杂问题,在强化学习训练中引入了语言一致性奖励,该奖励通过计算思维链中目标语言词汇的比例得出。尽管消融实验表明这种对齐会导致模型性能略有下降,但这种奖励符合人类偏好,使其更具可读性。最终,作者将推理任务的准确性与语言一致性奖励直接相加,形成最终奖励。随后,作者在微调后的模型上应用强化学习训练,直到其在推理任务上达到收敛。
拒绝采样与监督微调
当面向推理的强化学习收敛时,作者利用生成的ckpt收集监督微调(SFT)数据,用于下一轮训练。与初始冷启动数据主要关注reasoning不同,这一阶段还纳入了其他领域的数据,以增强模型在写作、角色扮演和其他通用任务中的能力。具体如下:
Reasoning data:在这一阶段,作者通过引入额外数据扩展了数据集,其中一些数据使用生成式奖励模型,将真实值与模型预测输入DeepSeek-V3进行判断。此外,由于模型输出有时混乱且难以阅读,作者过滤掉了语言混杂、长段落和代码块的思维链。对于每个提示词采样多个response,并仅保留正确的样本,总共收集了约60万条与推理相关的训练样本。
Non-reasoning data:对于非推理数据,如写作、事实问答、自我认知和翻译等,作者采用DeepSeek-V3的流程,并复用部分DeepSeek-V3的SFT数据集。对于某些非推理任务,作者调用DeepSeek-V3在回答问题前生成潜在的思维链,而对于简单的查询(如“你好”)不会提供思维链作为响应。最终收集了约20万条与推理无关的训练样本。
作者使用上述整理的约80万条样本对DeepSeek-V3-Base进行了两轮微调。
面向所有场景的强化学习 为了进一步使模型与人类偏好对齐,作者实施了第二阶段的强化学习,旨在提高模型的有用性和无害性,同时优化其推理能力
- 对于Reasoning数据,作者遵循DeepSeek-R1-Zero中概述的方法,使用基于规则的奖励来指导数学、代码和逻辑推理领域的学习过程
- 对于通用数据,依赖奖励模型来捕捉复杂和微妙场景中的人类偏好,基于DeepSeek-V3的流程,采用类似的偏好对分布和训练提示
- 对于有用性,仅关注最终总结,确保评估强调响应对用户的实用性和相关性,同时最小化对底层推理过程的干扰
- 对于无害性,评估模型的整个响应,包括推理过程和总结,以识别和缓解生成过程中可能出现的任何潜在风险、偏见或有害内容
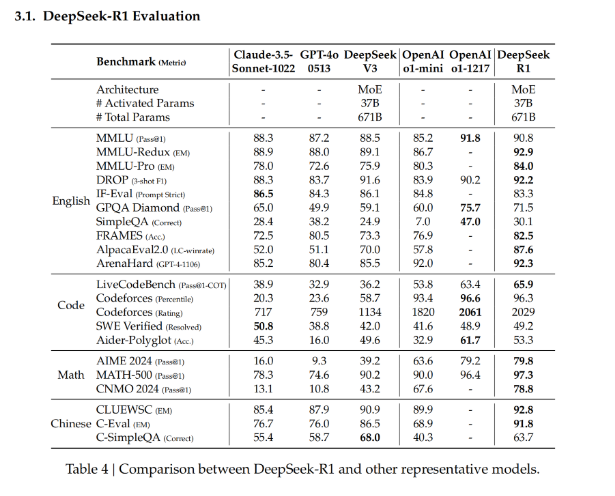
- 最终,通过整合奖励信号和多样化的数据分布,作者训练出了一个在推理方面表现出色,同时优先考虑有用性和无害性的模型
蒸馏小模型
为了让小型模型具备类似DeepSeek-R1的推理能力,作者直接使用DeepSeek-R1整理的80万条样本在开源模型(如Qwen和 Llama)上进行了模型蒸馏,使用的基础模型包括Qwen2.5-Math-1.5B、Qwen2.5-Math-7B、Qwen2.5-14B、Qwen2.5-32B、Llama-3.1-8B和Llama-3.3-70B-Instruct。对于蒸馏模型,作者仅应用监督微调(SFT),未包含强化学习阶段。