
MOE(混合专家)大模型技术详解-大模型
大模型-专栏, 上海市, 2026
MOE(Mixture of Experts,混合专家模型) 是一种神经网络架构设计范式,其核心思想是:将大型神经网络分解为多个相对独立的”专家”子网络,并通过门控机制(Gating Mechanism)动态选择激活部分专家来处理特定输入。
目录
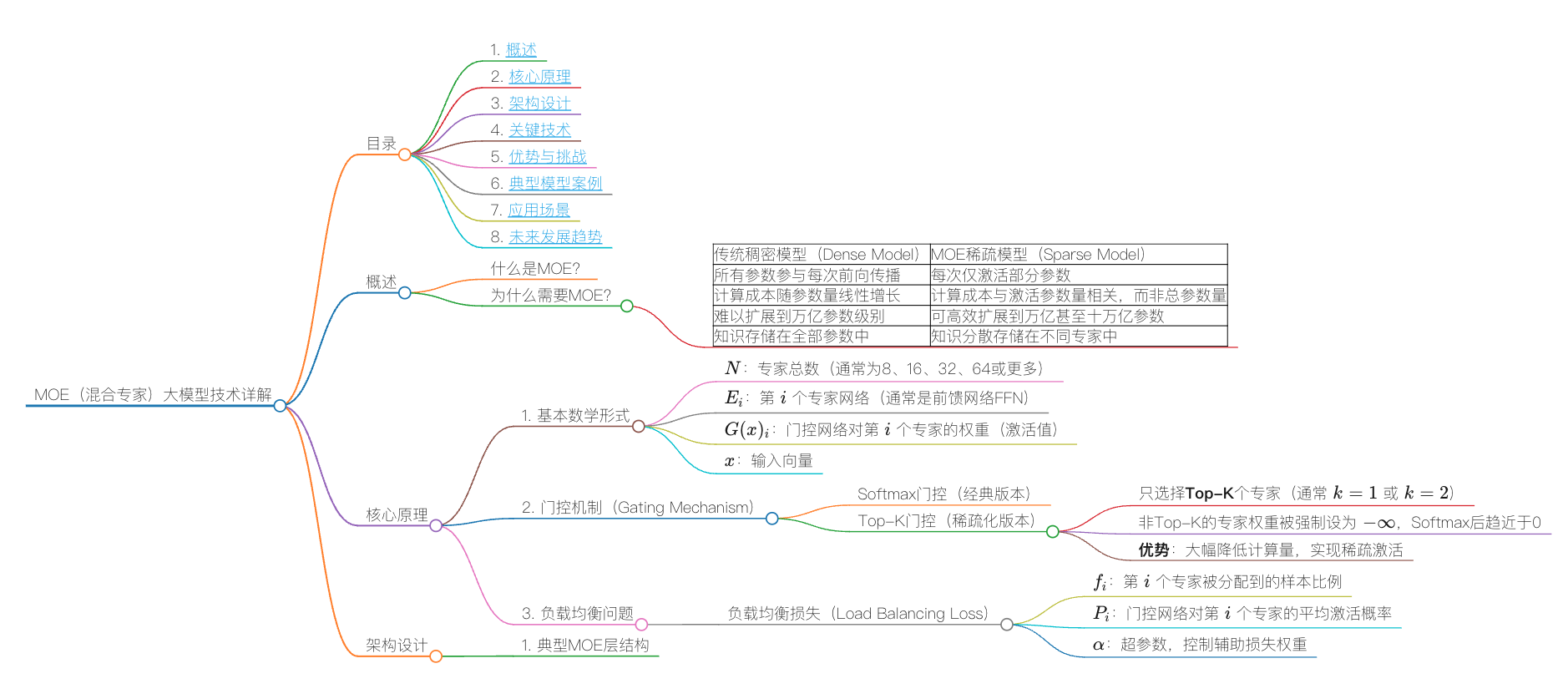
概述
什么是MOE?
MOE(Mixture of Experts,混合专家模型) 是一种神经网络架构设计范式,其核心思想是:将大型神经网络分解为多个相对独立的”专家”子网络,并通过门控机制(Gating Mechanism)动态选择激活部分专家来处理特定输入。
> 核心理念:不是让所有参数都参与每个输入的计算,而是”术业有专攻”,让不同的专家处理不同类型的任务或数据模式。
为什么需要MOE?
| 传统稠密模型(Dense Model) | MOE稀疏模型(Sparse Model) |
|---|---|
| 所有参数参与每次前向传播 | 每次仅激活部分参数 |
| 计算成本随参数量线性增长 | 计算成本与激活参数量相关,而非总参数量 |
| 难以扩展到万亿参数级别 | 可高效扩展到万亿甚至十万亿参数 |
| 知识存储在全部参数中 | 知识分散存储在不同专家中 |
关键优势:MOE允许模型在保持计算成本可控的前提下,大幅增加总参数量,从而显著提升模型的容量和表达能力。
核心原理
1. 基本数学形式
MOE层的输出可以表示为:
\[y = \sum_{i=1}^{N} G(x)_i \cdot E_i(x)\]其中:
- $N$:专家总数(通常为8、16、32、64或更多)
- $E_i$:第 $i$ 个专家网络(通常是前馈网络FFN)
- $G(x)_i$:门控网络对第 $i$ 个专家的权重(激活值)
- $x$:输入向量
2. 门控机制(Gating Mechanism)
门控网络是MOE的”指挥中心”,决定哪些专家应该被激活:
Softmax门控(经典版本)
\[G(x) = \text{Softmax}(W_g \cdot x + b)\]其中 $W_g \in \mathbb{R}^{N \times d}$,$d$ 为输入维度。
Top-K门控(稀疏化版本)
为了解决所有专家都被激活导致的计算冗余,现代MOE采用稀疏门控:
\[G(x) = \text{Softmax}(\text{TopK}(W_g \cdot x + b, k))\]- 只选择Top-K个专家(通常 $k=1$ 或 $k=2$)
- 非Top-K的专家权重被强制设为 $-\infty$,Softmax后趋近于0
- 优势:大幅降低计算量,实现稀疏激活
3. 负载均衡问题
稀疏门控带来一个关键挑战:负载不均衡——某些专家可能被过度使用,而另一些专家很少被激活。
负载均衡损失(Load Balancing Loss)
\[\mathcal{L}_{\text{aux}} = \alpha \cdot N \cdot \sum_{i=1}^{N} f_i \cdot P_i\]其中:
- $f_i$:第 $i$ 个专家被分配到的样本比例
- $P_i$:门控网络对第 $i$ 个专家的平均激活概率
- $\alpha$:超参数,控制辅助损失权重
目标:鼓励所有专家被均匀使用,避免”马太效应”。
架构设计
1. 典型MOE层结构
输入向量 x
↓
┌─────────────────┐
│ 门控网络 G │ ──→ 计算每个专家的权重
│ (Linear + Softmax)│
└─────────────────┘
↓
选择 Top-K 专家(例如 K=2)
↓
┌─────────────────────────────────────┐
│ 专家 0 专家 1 专家 2 … 专家 N-1 │
│ ↓ ↓ ↓ ↓ │
│ FFN₀ FFN₁ FFN₂ … FFNₙ₋₁ │
│ │ │ │ │ │
└─────────────────────────────────────┘
↓ (仅激活的 K 个专家进行计算)
加权求和: y = Σ G(x)ᵢ · Eᵢ(x)
↓
输出向量 y
2. 与Transformer的结合
现代大语言模型通常采用 “Transformer + MOE” 的混合架构:
输入: Token Embeddings ↓ [Transformer Block] × L₁层(稠密层) ↓ ┌─────────────────────────────────┐ │ MOE Transformer Block │ │ ┌─────────┐ ┌───────────┐ │ │ │ Self- │───→│ MOE │ │ │ │ Attention│ │ Layer │ │ │ └─────────┘ └───────────┘ │ │ (每K层替换FFN为MOE层) │ └─────────────────────────────────┘ ↓ [Transformer Block] × L₂层(稠密层) ↓ 输出: Logits
常见配置:
- 每隔1-4层将FFN替换为MOE层
- 保持Self-Attention层不变(通常不MOE化)
- 专家数量:8、16、32、64、128等
- 激活专家数:1-2个
3. 专家设计模式
| 模式 | 描述 | 代表模型 |
|---|---|---|
| 共享专家 | 所有专家共享部分参数 | DeepSeek-MoE |
| 细粒度专家 | 大量小型专家(如64个) | Mixtral 8x7B |
| 分层路由 | 多级门控,先选集群再选专家 | 早期Switch Transformer |
| 专家选择 | 让Token选择Top-K专家 | GLaM |
| 任务特定专家 | 不同专家处理不同任务类型 | 多任务学习场景 |
关键技术
1. 训练稳定性技术
MOE训练面临稳定性挑战:专家崩溃(Expert Collapse)、梯度消失等。
关键解决方案:
Z-Loss(路由器Z损失) \(\mathcal{L}_{z} = \frac{1}{B} \sum_{j=1}^{B} (\log \sum_{i=1}^{N} e^{z_{j,i}})^2\)
- 防止门控logits过大导致数值不稳定
- 鼓励门控输出保持适中范围
专家容量限制(Expert Capacity)
- 每个专家每批次最多处理 $C$ 个Token
- 超出容量的Token被标记为”溢出”,跳过该层或路由到下一专家
- 公式:$C = \frac{T \times K}{N} \times \text{capacity_factor}$
- $T$:Token总数,$K$:Top-K数,$N$:专家数
2. 高效并行策略
MOE训练需要特殊的分布式策略:
┌─────────────────────────────────────────┐ │ 数据并行 (Data Parallel) │ │ 每个GPU处理不同批次数据 │ └─────────────────────────────────────────┘ ↓ ┌─────────────────────────────────────────┐ │ 专家并行 (Expert Parallel) │ │ 不同专家分布在不同GPU上 │ │ 门控网络在所有GPU上复制 │ │ 通过All-to-All通信路由激活 │ └─────────────────────────────────────────┘ ↓ ┌─────────────────────────────────────────┐ │ 张量并行 (Tensor Parallel) │ │ 单个专家内部跨GPU切分 │ └─────────────────────────────────────────┘
通信优化:
- All-to-All通信:将Token路由到对应专家的GPU
- EP(Expert Parallelism)大小:通常等于专家数量
- DP(Data Parallelism)大小:总GPU数 / EP大小
3. 路由优化技术
| 技术 | 原理 | 效果 |
|---|---|---|
| Noisy Top-K | 门控 logits 添加少量噪声 | 增加路由随机性,改善负载均衡 |
| Expert Dropout | 训练时随机屏蔽部分专家 | 防止过度依赖,增强鲁棒性 |
| Load Balancing Biasing | 动态调整门控偏置 | 实时纠正负载不均衡 |
| Shared Expert Isolation | 分离共享专家和路由专家 | 捕获通用知识,减少冗余 |
优势与挑战
优势 ✅
- 规模扩展性
- 可轻松扩展到万亿参数(如1.6T参数的Switch-C)
- 计算成本仅随激活参数量增长,而非总参数量
- 任务专业化
- 不同专家自动学习不同语言模式、领域知识或任务类型
- 天然支持多任务学习
- 推理效率
- 推理时可仅加载激活专家到显存
- 支持专家卸载(Offloading)和动态加载
- 持续学习能力
- 新增任务时,可添加新专家而不干扰已有专家
- 支持模块化更新
挑战 ⚠️
| 挑战 | 具体表现 | 缓解策略 |
|---|---|---|
| 训练不稳定 | 专家崩溃、loss spike | Z-loss、梯度裁剪、预热策略 |
| 负载不均衡 | 部分专家过载,部分闲置 | 辅助损失、容量限制、动态路由 |
| 通信开销 | All-to-All通信成为瓶颈 | 优化通信拓扑、重叠计算与通信 |
| 显存碎片 | 不同批次激活不同专家 | 显存池管理、专家分页技术 |
| 微调困难 | 下游任务可能只需要部分专家 | 专家选择微调、LoRA适配 |
| 可解释性 | 专家分工不明确 | 可视化路由分布、专家分析 |
典型模型案例
1. GShard (Google, 2021)
- 架构:Transformer + MOE,每两层一个MOE层
- 规模:600B参数,每次激活约20B参数
- 创新:专家并行 + 数据并行混合策略
- 应用:机器翻译(100+语言)
2. Switch Transformer (Google, 2022)
- 架构:Top-1路由(每次只激活1个专家)
- 规模:1.6T参数,激活参数约50B
- 创新:简化路由策略,证明Top-1的有效性
- 特点:专家容量因子(Capacity Factor)概念
3. GLaM (Google, 2022)
- 规模:1.2T参数,64个专家/层,激活97B参数
- 创新:每个Token选择Top-2专家(非专家选Token)
- 性能:在多个NLP任务上超越GPT-3,训练能耗更低
4. Mixtral 8x7B / 8x22B (Mistral AI, 2023-2024)
- 架构:8个专家,Top-2路由
- 特点:开源、高性能,可本地部署
- 性能:8x7B版本在多项基准测试超越Llama 2 70B
- 创新:滑动窗口注意力 + MOE结合
5. DeepSeek-V2/V3 (DeepSeek, 2024)
- 架构:MLA(Multi-head Latent Attention)+ DeepSeekMoE
- 创新:细粒度专家 + 共享专家分离
- 特点:极高的性价比,训练成本极低
- 规模:V3达671B参数,每次激活37B参数
6. Qwen1.5-MoE / Qwen2.5-MoE (阿里, 2024)
- 架构:基于Qwen架构的MOE版本
- 特点:支持多种专家配置(如14B激活/72B总参数)
- 创新:路由专家与共享专家协同设计
应用场景
1. 大语言模型(LLM)
- 多语言处理:不同专家处理不同语系
- 代码生成:专门专家处理编程语言
- 数学推理:特定专家增强逻辑能力
2. 多模态模型
- 视觉-语言模型:专家分别处理图像、文本、跨模态融合
- 视频理解:时序专家、空间专家分离
3. 推荐系统
- 用户分群:不同专家服务不同用户群体
- 内容类型:图文、视频、商品各自有专家处理
4. 科学计算
- 分子模拟:不同专家学习不同分子相互作用模式
- 气候预测:时空分离的专家架构
未来发展趋势
1. 架构演进
- 细粒度MOE:更多小型专家(256+),更细的专业分工
- 分层路由:多级门控,先粗分后细分
- 动态专家:训练过程中动态添加/删除专家
- 条件计算:不仅选择专家,还动态决定计算深度
2. 高效推理
- 专家缓存:热点专家常驻显存,冷专家按需加载
- 推测解码 + MOE:Draft模型与MOE结合
- 边缘部署:专家卸载到CPU/磁盘,仅激活专家在GPU
3. 训练优化
- 专家并行新拓扑:3D并行(DP+EP+TP+PP)进一步优化
- 异步路由:解耦路由计算与专家计算
- 专家正则化:防止专家同质化,增强多样性
4. 与新技术结合
| 技术方向 | 结合方式 | 潜在收益 |
|---|---|---|
| 长上下文 | 专家专门处理不同上下文区间 | 降低长文本注意力成本 |
| RAG | 专家专门处理检索知识融合 | 提升知识利用效率 |
| Agent | 专家对应不同工具/技能 | 增强工具调用能力 |
| 神经架构搜索 | 自动学习最优专家配置 | 摆脱手工设计 |
总结
MOE架构通过“分而治之”的策略,为大模型扩展提供了一条高效路径。其核心在于:
- 稀疏激活:用计算换容量,突破稠密模型规模限制
- 专业化分工:自动学习任务分解,提升模型表达能力
- 系统级优化:需要算法、框架、硬件协同设计
随着DeepSeek-V3、Mixtral等开源模型的成功,MOE正从研究概念走向工程实践,成为下一代大模型的标准配置之一。未来,随着专家并行效率的提升和动态路由技术的发展,“万亿参数、消费级推理”的愿景正在逐步成为现实。
参考资源
- 论文:
- “Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer” (2017)
- “GShard: Scaling Giant Models with Conditional Computation” (2021)
- “Switch Transformers: Scaling to Trillion Parameter Models” (2022)
- “Mixtral of Experts” (2024)
- “DeepSeekMoE: Towards Ultimate Expert Specialization” (2024)
- 开源实现:
- Megatron-LM (NVIDIA)
- DeepSpeed-MoE (Microsoft)
- Fairseq-MoE (Meta)
- vLLM (支持MOE推理加速)