
XGboost进行时间序列预测
Xgboost专栏, 上海市, 2023
XGBoost是一个优化的分布式梯度增强库,旨在实现高效,灵活和便携。 它在 Gradient Boosting 框架下实现机器学习算法。XGBoost提供并行树提升(也称为GBDT,GBM),可以快速准确地解决许多数据科学问题。相同的代码在主要的分布式环境(Hadoop,SGE,MPI)上运行,并且可以解决数十亿个示例之外的问题。XGBoost [2]是对梯度提升算法的改进,求解损失函数极值时使用了牛顿法,将损失函数泰勒展开到二阶,另外损失函数中加入了正则化项。
1)导入依赖包
导入了一些常用的数据分析和可视化库,以及XGBoost模型。
import pandas as pd: 导入pandas库,用于数据处理和分析。import numpy as np: 导入NumPy库,用于数值计算和数组操作。import matplotlib.pyplot as plt: 导入matplotlib库,用于绘制图表。import seaborn as sns: 导入seaborn库,用于统计数据可视化。import xgboost as xgb: 导入XGBoost库,用于实现梯度提升树模型。from sklearn.metrics import mean_squared_error: 从scikit-learn库中导入均方误差(mean squared error)评估指标。color_pal = sns.color_palette(): 使用seaborn库中的颜色调色板设置颜色样式。plt.style.use('fivethirtyeight'): 使用matplotlib库中的样式设置为”fivethirtyeight”风格,该风格通常用于数据可视化。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import xgboost as xgb
from sklearn.metrics import mean_squared_error
color_pal = sns.color_palette()
plt.style.use('fivethirtyeight')
2)读取数据
这段代码读取了名为’PJME_hourly.csv’的CSV文件,并对数据进行了处理和预览。以下是代码的解释:
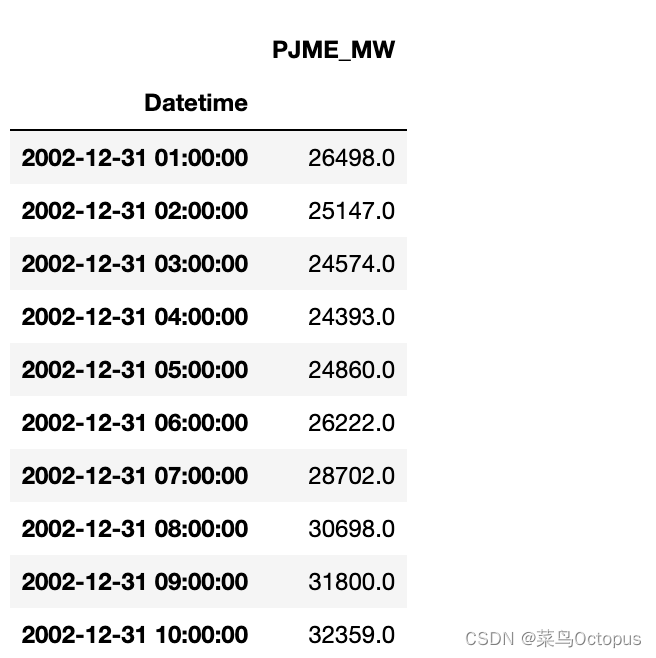
df = pd.read_csv('PJME_hourly.csv'):使用pandas库的read_csv函数读取名为’PJME_hourly.csv’的CSV文件,并将其存储到DataFrame对象df中。df = df.set_index('Datetime'):将’Datetime’列设置为DataFrame的索引列。df.index = pd.to_datetime(df.index):将索引列的数据转换为datetime类型,以便进行日期和时间的处理。df.head(10):显示DataFrame的前10行数据,用于预览数据集的内容。
df = pd.read_csv('PJME_hourly.csv')
df = df.set_index('Datetime')
df.index = pd.to_datetime(df.index)
df.head(10)
3) 数据预览
使用matplotlib和pandas绘制了数据集中的折线图,并显示在图形界面中。 以下是代码的解释:
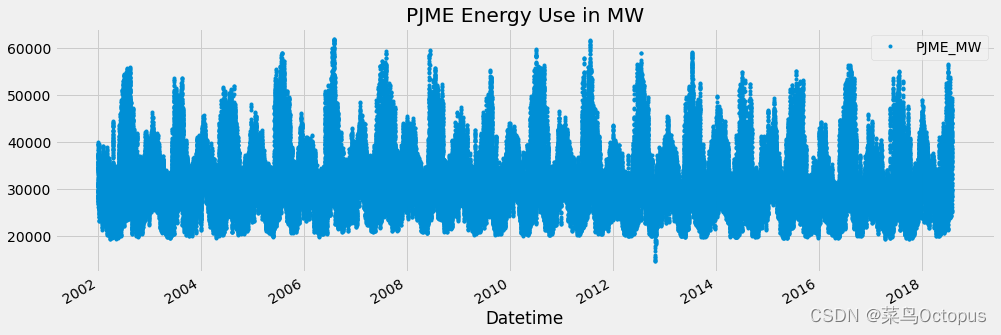
df.plot(style='.', figsize=(15, 5), color=color_pal[0], title='PJME Energy Use in MW'):使用DataFrame的plot函数绘制折线图。其中, -style='.'表示以点状的样式绘制折线图。 -figsize=(15, 5)指定图形的尺寸为宽度15英寸,高度5英寸。 -color=color_pal[0]设置折线的颜色,color_pal[0]表示使用颜色调色板中的第一个颜色。 -title='PJME Energy Use in MW'为图形设置标题为’PJME Energy Use in MW’。plt.show():显示绘制的图形。
df.plot(style='.',
figsize=(15, 5),
color=color_pal[0],
title='PJME Energy Use in MW')
plt.show()
4)训练集合验证码集切割
将数据集划分为训练集和测试集,并绘制了训练集和测试集的折线图,以及分割线。 以下是代码的解释:
train = df.loc[df.index < '01-01-2015']:将日期在’01-01-2015’之前的数据作为训练集,通过索引筛选出相应的数据。test = df.loc[df.index >= '01-01-2015']:将日期在’01-01-2015’及之后的数据作为测试集,通过索引筛选出相应的数据。fig, ax = plt.subplots(figsize=(15, 5)):创建一个图形对象和一个坐标轴对象,设置图形的尺寸为宽度15英寸,高度5英寸。train.plot(ax=ax, label='Training Set', title='Data Train/Test Split'):使用训练集的数据在坐标轴上绘制折线图,设置标签为’Training Set’,设置标题为’Data Train/Test Split’。test.plot(ax=ax, label='Test Set'):使用测试集的数据在同一坐标轴上绘制折线图,设置标签为’Test Set’。ax.axvline('01-01-2015', color='black', ls='--'):在坐标轴上绘制垂直线,表示训练集和测试集之间的分割线,日期为’01-01-2015’,颜色为黑色,线条样式为虚线。ax.legend(['Training Set', 'Test Set']):在图形中添加图例,分别对应训练集和测试集。plt.show():显示绘制的图形。 ```python train = df.loc[df.index < ‘01-01-2015’] test = df.loc[df.index >= ‘01-01-2015’]
fig, ax = plt.subplots(figsize=(15, 5)) train.plot(ax=ax, label=’Training Set’, title=’Data Train/Test Split’) test.plot(ax=ax, label=’Test Set’) ax.axvline(‘01-01-2015’, color=’black’, ls=’–’) ax.legend([‘Training Set’, ‘Test Set’]) plt.show()
<br/><img src='/images/xgb3.png'>
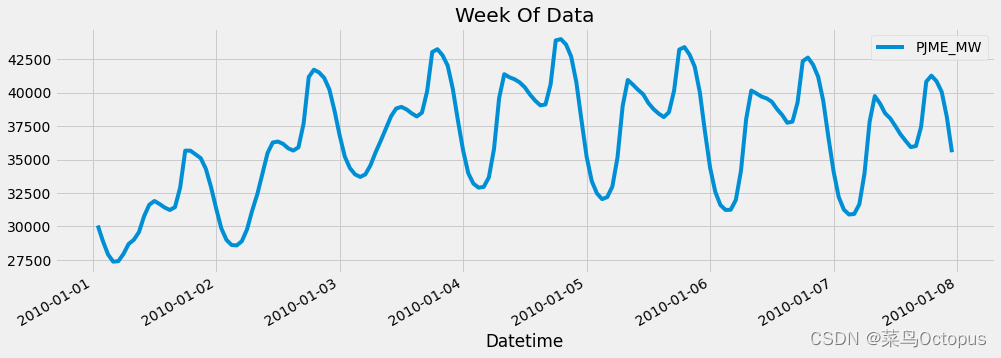
从数据集中选择了日期在 '01-01-2010' 和 '01-08-2010' 之间的数据,并绘制了这段时间内的折线图。
以下是代码的解释:
1. `df.loc[(df.index > '01-01-2010') & (df.index < '01-08-2010')]`:通过索引筛选出日期在 '01-01-2010' 和 '01-08-2010' 之间的数据。
2. `.plot(figsize=(15, 5), title='Week Of Data')`:使用所选数据在图形上绘制折线图,设置图形的尺寸为宽度15英寸,高度5英寸,并设置标题为 'Week Of Data'。
3. `plt.show()`:显示绘制的图形。
```python
df.loc[(df.index > '01-01-2010') & (df.index < '01-08-2010')] \
.plot(figsize=(15, 5), title='Week Of Data')
plt.show()
5)特征提取
create_features 函数接受一个时间序列数据框 df 作为输入,并根据时间序列索引创建一系列时间相关的特征。具体的特征包括小时、星期几、季度、月份、年份、年内第几天、日期和年内第几周。这些特征从时间序列索引中提取,并以新的特征列的形式添加到数据框中。函数返回添加了时间序列特征的数据框 df。通过这种方式,我们可以从时间序列数据中捕捉到不同时间尺度上的变化模式和周期性信息。
def create_features(df):
"""
Create time series features based on time series index.
"""
df = df.copy()
df['hour'] = df.index.hour
df['dayofweek'] = df.index.dayofweek
df['quarter'] = df.index.quarter
df['month'] = df.index.month
df['year'] = df.index.year
df['dayofyear'] = df.index.dayofyear
df['dayofmonth'] = df.index.day
df['weekofyear'] = df.index.isocalendar().week
return df
df = create_features(df)
6)可视化特征
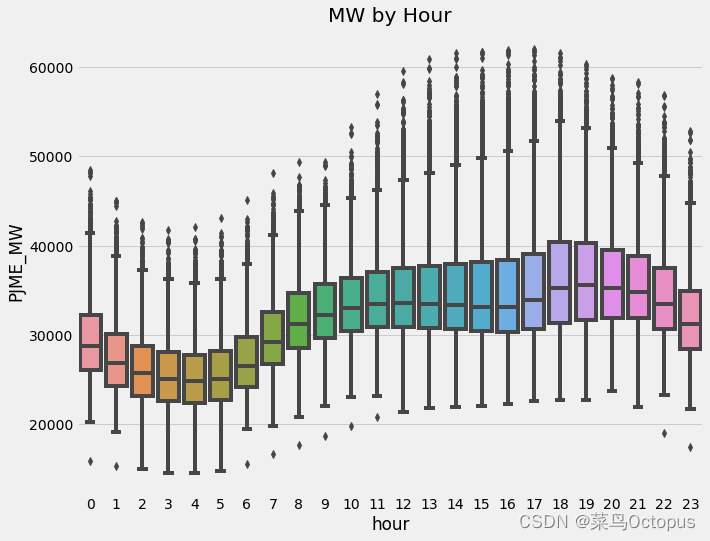
使用seaborn库创建一个箱线图,用于展示不同时间段内’PJME_MW’(兆瓦)变量的分布情况。箱线图展示了每个小时的中位数、四分位数以及可能存在的异常值。x轴表示一天中的小时,y轴表示’PJME_MW’的取值。通过箱线图可以了解一天中不同时间段能量使用量的变化和集中趋势,帮助我们理解能源在不同小时的变化情况。
fig, ax = plt.subplots(figsize=(10, 8))
sns.boxplot(data=df, x='hour', y='PJME_MW')
ax.set_title('MW by Hour')
plt.show()
使用seaborn库创建一个箱线图,用于展示不同月份内’PJME_MW’(兆瓦)变量的分布情况。箱线图展示了每个月的中位数、四分位数以及可能存在的异常值。x轴表示月份,y轴表示’PJME_MW’的取值。通过箱线图可以了解不同月份能量使用量的变化和集中趋势,该图使用了蓝色调色板进行可视化。箱线图的生成有助于我们了解能源使用在不同月份的变化情况。
fig, ax = plt.subplots(figsize=(10, 8))
sns.boxplot(data=df, x='month', y='PJME_MW', palette='Blues')
ax.set_title('MW by Month')
plt.show()
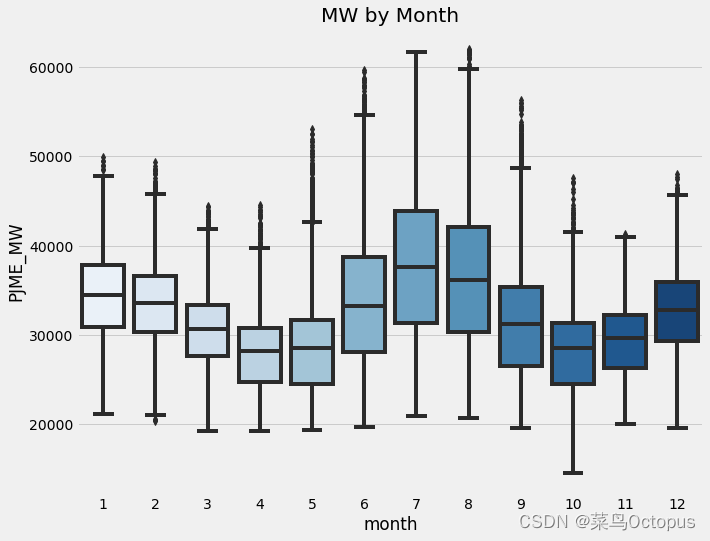
7)训练模型
首先对训练集和测试集应用了create_features函数,为时间序列数据创建了一些基于时间索引的特征。然后,定义了特征列名FEATURES和目标列名TARGET,其中FEATURES包含了用于训练和预测的特征列,TARGET是要预测的目标列。
接下来,将训练集中的特征和目标分别赋值给X_train和y_train,用于训练模型。X_train包含了训练集的特征数据,而y_train包含了对应的目标数据。
类似地,将测试集中的特征和目标分别赋值给X_test和y_test,用于模型的测试和评估。
通过这些操作,我们准备好了训练集和测试集的特征数据和目标数据,以便进行后续的模型训练和预测。
train = create_features(train)
test = create_features(test)
FEATURES = ['dayofyear', 'hour', 'dayofweek', 'quarter', 'month', 'year']
TARGET = 'PJME_MW'
X_train = train[FEATURES]
y_train = train[TARGET]
X_test = test[FEATURES]
y_test = test[TARGET]
创建了一个XGBoost回归器(xgb.XGBRegressor),用于训练和预测。设置了一些参数来配置回归器的行为,包括基础分数(base_score)、提升器(booster)、估计器数量(n_estimators)、早停轮数(early_stopping_rounds)、目标函数(objective)、最大深度(max_depth)和学习率(learning_rate)。
然后,使用fit方法对回归器进行训练。训练数据是X_train和y_train,并且通过eval_set参数提供了训练集和测试集的数据用于评估。设置了verbose参数为100,以便在训练过程中显示进度和评估结果。
通过这些操作,完成了XGBoost回归器的训练过程,并且模型可以用于进行预测。
reg = xgb.XGBRegressor(base_score=0.5, booster='gbtree',
n_estimators=1000,
early_stopping_rounds=50,
objective='reg:linear',
max_depth=3,
learning_rate=0.01)
reg.fit(X_train, y_train,
eval_set=[(X_train, y_train), (X_test, y_test)],
verbose=100)
[17:13:00] WARNING: ../src/objective/regression_obj.cu:170: reg:linear is now deprecated in favor of reg:squarederror. [17:13:00] WARNING: ../src/learner.cc:541: Parameters: { early_stopping_rounds } might not be used. This may not be accurate due to some parameters are only used in language bindings but passed down to XGBoost core. Or some parameters are not used but slip through this verification. Please open an issue if you find above cases. [0] validation_0-rmse:32605.13672 validation_1-rmse:31657.16602 [100] validation_0-rmse:12581.21582 validation_1-rmse:11743.75195 [200] validation_0-rmse:5835.12500 validation_1-rmse:5365.67725 [300] validation_0-rmse:3915.75537 validation_1-rmse:4020.67041 [400] validation_0-rmse:3443.16480 validation_1-rmse:3853.40454 [500] validation_0-rmse:3285.33838 validation_1-rmse:3805.30176 [600] validation_0-rmse:3201.92920 validation_1-rmse:3772.44922 [700] validation_0-rmse:3148.14209 validation_1-rmse:3750.91089 [800] validation_0-rmse:3109.24292 validation_1-rmse:3733.89697 [900] validation_0-rmse:3079.40063 validation_1-rmse:3725.61231 [999] validation_0-rmse:3052.73511 validation_1-rmse:3722.92236
8)特征重要性
创建了一个数据框(fi)来存储XGBoost回归器中各个特征的重要性。重要性值通过reg.feature_importances_获取,并与特征名称(FEATURES)一起存储在数据框中,列名为”importance”。
然后,通过调用sort_values对数据框按照重要性值进行排序,并使用plot函数绘制水平条形图(kind='barh')来展示特征的重要性。最后,使用plt.show()显示图形。 目的是可视化特征的重要性,以帮助理解和解释模型的预测结果。 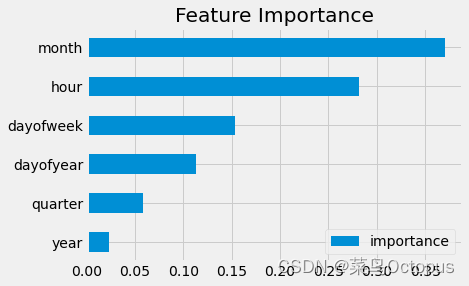
fi = pd.DataFrame(data=reg.feature_importances_,
index=FEATURES,
columns=['importance'])
fi.sort_values('importance').plot(kind='barh', title='Feature Importance')
plt.show()
9)测试集可视化
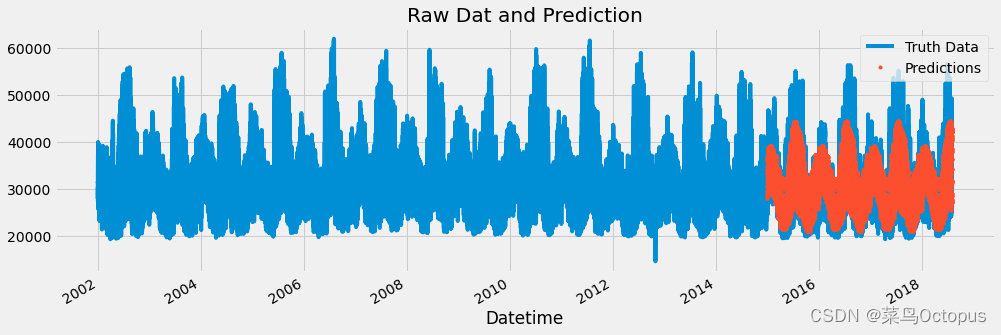
将测试集(test)中的预测结果添加到原始数据集(df)中,将预测结果列命名为”prediction”。通过使用merge函数将test[['prediction']]与df进行左连接,连接键为时间索引。
接下来,创建一个图形对象(ax),并在图形上绘制原始数据列(“PJME_MW”)的折线图。然后,使用.plot函数将预测结果列(“prediction”)以点的形式绘制在图形上。通过使用plt.legend为图形添加图例,标识出”Truth Data”和”Predictions”。最后,通过调用ax.set_title设置图形的标题,并使用plt.show()显示图形。
可视化原始数据与模型的预测结果,以便进行比较和评估模型的性能。
test['prediction'] = reg.predict(X_test)
df = df.merge(test[['prediction']], how='left', left_index=True, right_index=True)
ax = df[['PJME_MW']].plot(figsize=(15, 5))
df['prediction'].plot(ax=ax, style='.')
plt.legend(['Truth Data', 'Predictions'])
ax.set_title('Raw Dat and Prediction')
plt.show()
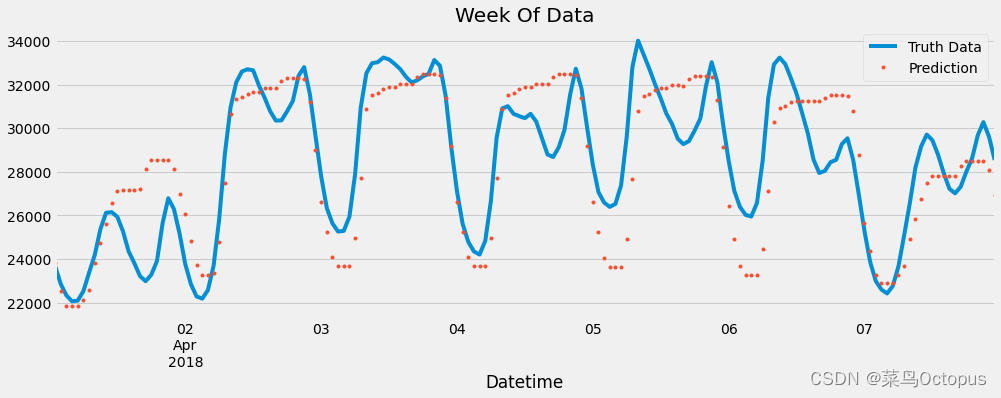
创建了一个图形对象(ax),并在图形上绘制了指定时间范围内(“04-01-2018”到”04-08-2018”)的原始数据列(“PJME_MW”)的折线图。然后,使用.plot函数以点的形式绘制了相同时间范围内的预测结果列(“prediction”)。
通过调用plt.legend为图形添加图例,标识出”Truth Data”和”Prediction”。最后,使用plt.show()显示图形。
可视化指定时间范围内的原始数据和相应的模型预测结果,以便进行比较和评估模型的性能。
ax = df.loc[(df.index > '04-01-2018') & (df.index < '04-08-2018')]['PJME_MW'] \
.plot(figsize=(15, 5), title='Week Of Data')
df.loc[(df.index > '04-01-2018') & (df.index < '04-08-2018')]['prediction'] \
.plot(style='.')
plt.legend(['Truth Data','Prediction'])
plt.show()
10) RMSE计算
计算测试集中原始数据列(“PJME_MW”)和预测结果列(“prediction”)之间的均方根误差(RMSE)分数。使用mean_squared_error函数计算均方根误差,然后使用np.sqrt函数取平方根,得到最终的RMSE分数。
通过打印输出,将RMSE分数格式化为两位小数,并显示在屏幕上,以评估模型在测试集上的性能。
score = np.sqrt(mean_squared_error(test['PJME_MW'], test['prediction']))
print(f'RMSE Score on Test set: {score:0.2f}')
RMSE Score on Test set: 3722.92
### 11)计算误差 它计算测试集中每个日期的预测误差的平均值,并按降序排列,然后输出前10个日期及其对应的平均误差。
首先,通过计算test[TARGET]和test['prediction']之间的绝对误差,将误差存储在test['error']列中。然后,将日期从时间戳中提取出来,并存储在test['date']列中。接下来,使用groupby方法按日期进行分组,并计算每个日期的误差平均值。最后,使用sort_values方法按降序对平均误差进行排序,并使用head(10)选择前10个日期。
输出结果显示了前10个日期及其对应的平均误差值。
test['error'] = np.abs(test[TARGET] - test['prediction'])
test['date'] = test.index.date
test.groupby(['date'])['error'].mean().sort_values(ascending=False).head(10)
date 2016-08-13 12853.568034
2016-08-14 12796.636312
2016-09-10 11369.115967
2015-02-20 10931.238200
2016-09-09 10877.764323
2018-01-06 10475.434652
2016-08-12 10138.022217
2015-02-21 9847.064535
2015-02-16 9753.021729
2018-01-07 9710.187744
Name: error, dtype: float64