
Xgboost原理介绍
Xgboost专栏, 上海市, 2024
本文不讲如何使用 XGBoost 也不讲如何调参,主要会讲一下作为 GBDT 中的一种,XGBoost 的原理与相关公式推导。为了循序渐进的理解,读者可先从简单的回归树再到提升树再来看本文。我们现在直接从 XGBoost 的目标函数讲起。
XGBoost 公式推导
XGBoost 的目标函数如下: 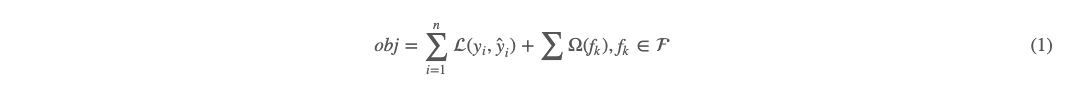 上面的两项加号前项为在训练集上的损失函数。其中 yi 表示真实值,ŷ iy^i 表示预测值。加号后项为正则项,到后面再看 Ω 这个函数的具体形式。我们现在只需要知道 Ω 的自变量为 fk,是决策树,而不是向量,所以是没有办法用和导数有关的方法来训练的(像梯度下降等)。
上面的两项加号前项为在训练集上的损失函数。其中 yi 表示真实值,ŷ iy^i 表示预测值。加号后项为正则项,到后面再看 Ω 这个函数的具体形式。我们现在只需要知道 Ω 的自变量为 fk,是决策树,而不是向量,所以是没有办法用和导数有关的方法来训练的(像梯度下降等)。
Boosting
何为 Boosting,这个可以主要在上面给的提升树文章中去了解。这里大概描述如下: 
依此类推,每次迭代轮数均比上次迭代好一些,通式如下: 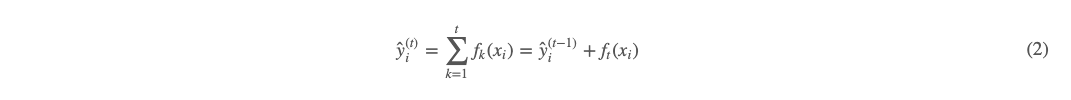
上面 (2) 式即为对于第 t 轮的 boosting 公式。我们再看此时的目标函数: 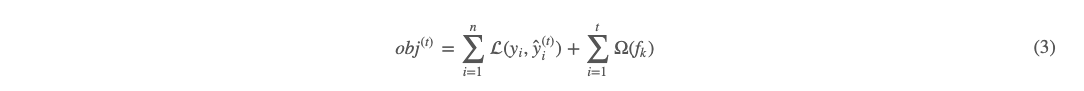
其中 (3) 式 n 为样本数,t 为树的棵数,也是迭代的轮数,yi 为真实值,ŷ iy^i 为第 t 轮的预测值 。对于正则化项,又可以写成如下形式: 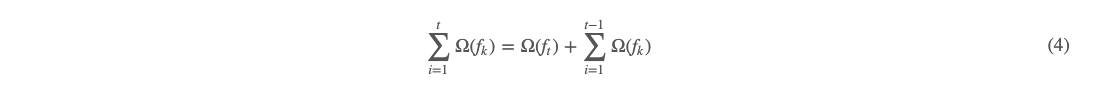 (4) 式这么写有什么好处呢?因为我们的方法是 boosting 逐轮计算的,所以当计算第 tt 轮时,前面 t−1 轮事实上是已经计算出来了的。即 (4) 式的加号后项为常数。所以把 (2)(4) 式代入 (3) 式,有如下:
(4) 式这么写有什么好处呢?因为我们的方法是 boosting 逐轮计算的,所以当计算第 tt 轮时,前面 t−1 轮事实上是已经计算出来了的。即 (4) 式的加号后项为常数。所以把 (2)(4) 式代入 (3) 式,有如下: 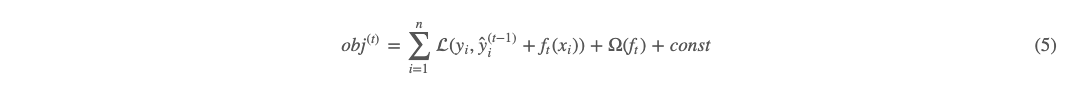
Taylor 展开
在 (5) 这个式子的基础上,我们就可以做点文章了。我们现在假定经验损失 L 是可以二阶 Taylor 展开的。把 ft(xi) 当成无穷小,就得到了如下式:
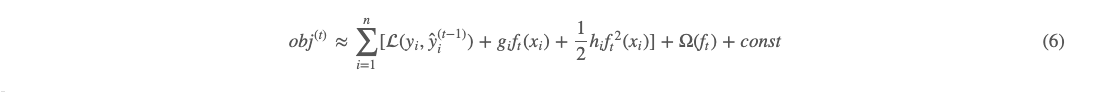
(6) 这个式子是比较抽象的,为帮助对 gi 和 hi的理解,我们把常见的平方损失函数代入 (5) 可有:
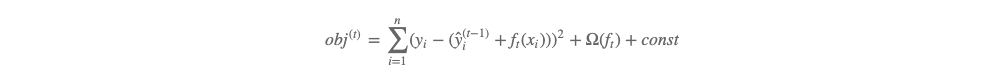
展开有: 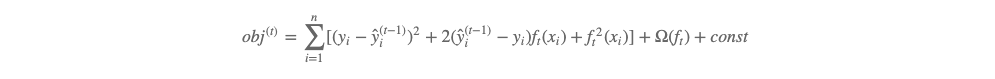
即: 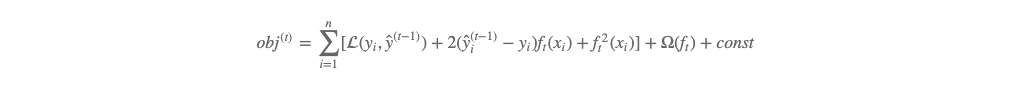
套用一下 (6) 式,即有当损失函数为平方损失时 gi=2(ŷ (t−1)i−yi)gi=2(y^i(t−1)−yi),hi=2hi=2。
我们再考察 (6) 式,其中的 (yi,ŷ (t−1)i)L(yi,y^i(t−1)) 意义是 t−1 轮的经验损失,在执行第 t 轮的时候,这一项其实已经也是一个已知的常数。那么优化目标就可以继续简化如下:
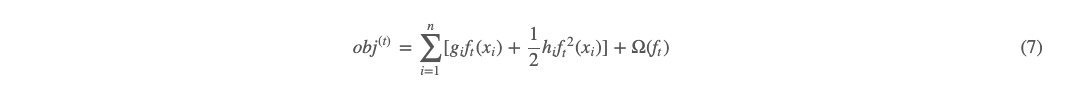
其中,gi 和 hi 可根据 Taylor 公式求得如下:

也就是说在给定损失函数的形式,则 gi 和 hi 就可以算出来。
树的权重求解与结构分
我们从 (7) 式再往下,把 ft(x) 搞清楚。有:
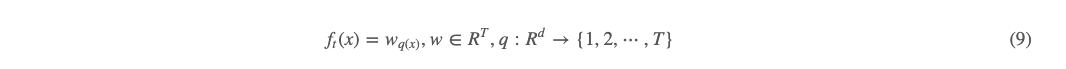
ft(x) 表示第 tt棵树,x 为输入特征,其维数为 d,ft(x) 即为把特征映射到一个树的叶子结点上的一个数(权重),ft(x) 可以分为 w 和 q 两部分,其中 q 为把特征映射到一个 T 个叶子结点的函数,相当于是决策树的结构。w 为把每个叶子结点映射为其权重值。
树的函数搞清了,如果没有搞清楚,可以从本文开头提到的回归树原理与推导和提升树原理与推导再深入学习一下。
我们考察 (7) 式中的罚项 Ω(ft),这个罚项是用来惩罚树的复杂程度的。根据上面 ft(x) 的描述,我们可以从树的结构与树叶子结点上的权重做罚项,我们定义如下:
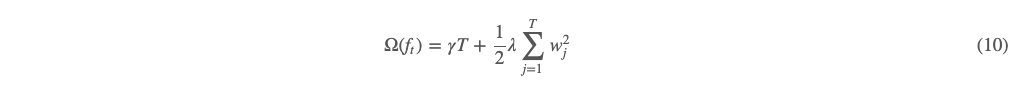
其中 T 为叶子节点个数,ww 为叶子节点权重。我们把 (10) 式加号前项叫 L0范数,加号后项为 L2范数,γ 和 λ 分别为各自超参数。
我们把 (10) 式,(9) 式都代入 (7) 式,有:
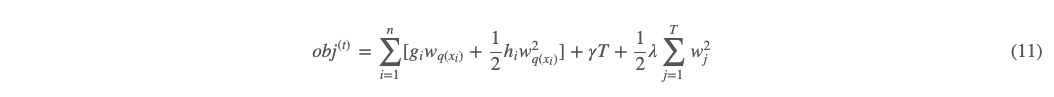
到这里,我们可以看到 (7) 式中优化事实上可以着重分为两大步,第一步拿到树结构,第二步再计算叶子节点上的权重大小。我们先令:
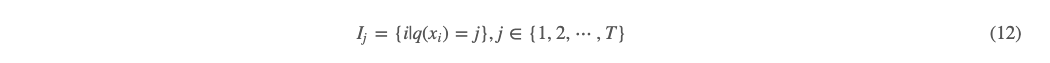
(12) 式的意思是定义所有落在第 j 个叶子节点的样本为 Ij,即被映射到第 j 个叶子节点上的所有样本 xi 的索引。那么对 (11) 式按树的叶子节点分组重写如下:
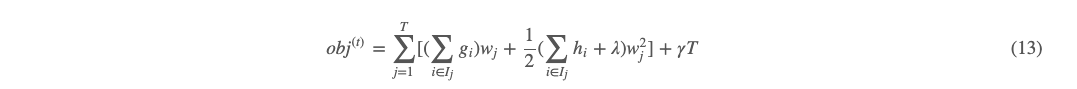
我们令 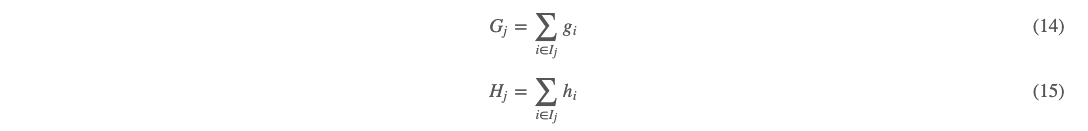
把 (14)(15) 代入 (13) 有:
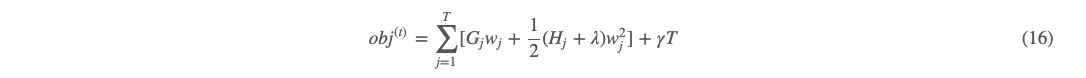
我们假定这时候树的结构已经知道,那么映射到叶子节点 j 上面的样本索引就固定了,而损失函数也是已知的,由 (8) 可有 gi 和 hi 都是已知的,进而 Gj 和 Hj 则都是已知的。那么,目标函数就变成了求叶子节点个数 T 个的关于 w 的一元二次函数求和的形式,而且他们两两之间都是独立的。接下来我们对每个 ww 进行求解,用到的就是高中数学知识了。对于每个这个形式的一元二次函数,可有取极值时的 w:
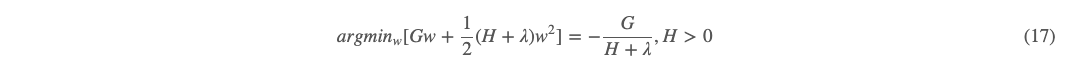
这个时候极值为:
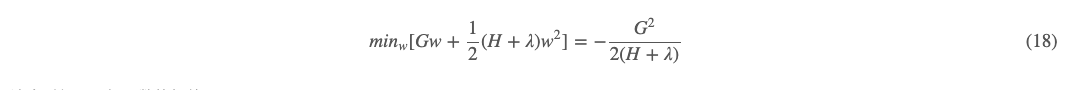
即这个时候,目标函数的极值:
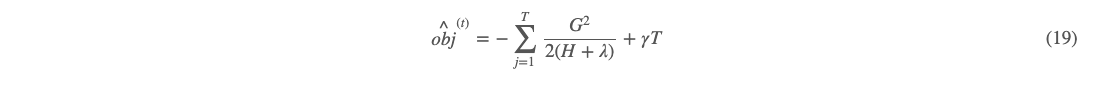
也被称为树的结构分。
到这里,我们解决了一个问题,就是在知道每轮的树的结构 q 的前提下,我们能够很快求得每个叶子节点上的最优权重值 w。
如何找到最优的树结构
那么如何获取最优的树结构呢?方式一:遍历所有可能的树结构,计算每种可能的树的结构分,然后再找到最小结构分对应的权重。这种方式可想而知根本无法实际应用。方式二:基于贪心策略,每次分裂都使得分裂后的增益最大。这种方式其实与决策树的树基本生成算法类似,只是增益的定义不一样。我们这里的增益可以用树的结构分来定义,每次树的分裂点使得整体树的结构分下降得最大,定义如下: 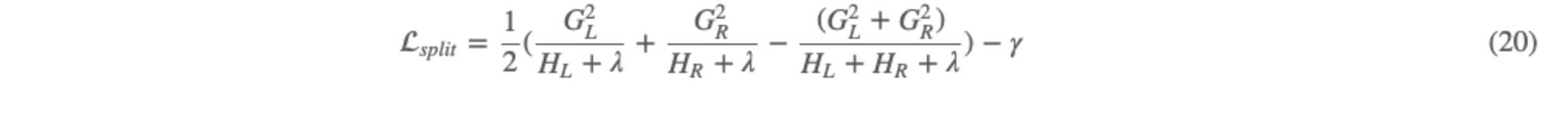
总结
我们对本文从上到下总结一下。XGBoost 首先确定好树的棵数。对于每轮的那棵树,其形成步骤大体可以分为两大块,第一要先确定好树的最优结构,一般会根据树的结构分下降最大的分裂点进行贪心算法构造,当然这里会有一些单棵树的深度或者叶子节点数限制。当树的结构确定好之后,对于每个叶子节点的权重,可以很快地用一元二次函数解法求得。当此轮的树生成完毕后,即可求得每个样本的预测结果,从而进行下一轮迭代。
参考文献
XGBoost: A Scalable Tree Boosting System