
一、论文简介
批判性地分析了深度学习模型设计的不足,通过将复杂的深度学习模型线性化,证明即使简化后的模型也能保持相似的性能。呼吁TAD领域需要新的、更丰富的数据集,改进评价指标,对复杂模型保持谨慎态度,关注简单和可解释的方法。
主要贡献:
- 引入了简单有效的基线,并证明它们的性能与SOTA方法相当或更好,从而挑战了增加模型复杂性来解决TAD问题的效率和有效性。
- 通过将训练的SOTA模型简化为线性模型来加强这一立场,线性模型是它们的蒸馏,但仍然表现良好。
因此,从当前数据集上的TAD任务的角度来看,这些模型大致上将异常与标准数据进行了线性分离。
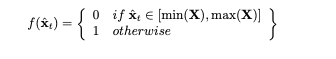
- L2-norm: Magnitude of the observed time stamp(范数)
在多元时间序列数据的情况下,向量在特定时间戳的大小可以作为检测OOD样本的相关统计量。这可以很容易地通过取向量的l2范数来计算,因此$f(\hat{x}_t)=\parallel \hat{x}_t \parallel_2$。通过使用幅值为异常评分。
- NN-distance: Nearest neighbor distance to the normaltraining data
异常样本与正常数据的距离应该更大。因此,使用每个测试集时间戳和训练数据之间的最近邻距离(欧氏距离)作为异常评分可以作为可靠的基线。事实上,在许多情况下,这种方法比一些最先进的技术要好。
- PCA reconstruction error
对训练集拟合一个PCA模型,对测试集使用该模型后,再进行pca.inverse_transform重建,重建误差作为异常分数。
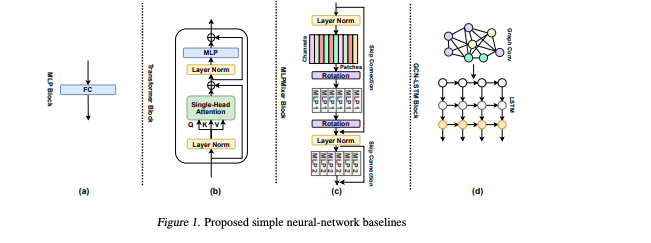
2.2 提出的神经网络基线
- layer linear MLP as auto-encoder:无激活函数
- Single Transformer block:一个单头注意力和一个全连接层
- Single block MLP-Mixer:token混合子层和通道混合子层。它们对输入特征映射的空间维度和通道维度进行操作。
- 1-layer GCN-LSTM block
2.3 评价指标
- 精确度是预测的异常区间与真实异常区间的交集与预测异常区间长度的比值的平均。
- 召回率是真实异常区间与预测异常区间的交集与真实异常区间长度的比值的平均。
- γ函数用于对每个预测区间的权重进行调整
三、实验
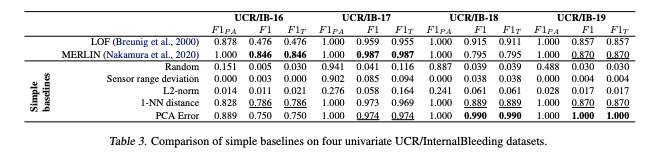
中使用了六个常用的基准数据集。在这里,我们报告了三个多变量数据集(SWaT、WADI和SMD)和四个单变量数据集(UCR/内出血)的细节(表1)和结果。另外两个常用的多变量数据集(SMAP和MSL)已在(Wu & Keogh, 2022)中被确定为潜在的缺陷,包含琐碎和不现实的异常密度。
实验结果: 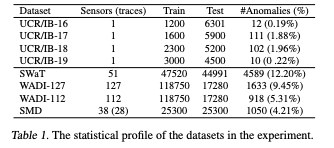
Random:每个时间戳预测异常的概率为0.5,我们报告在五次独立运行中获得的分数。
实验结果:
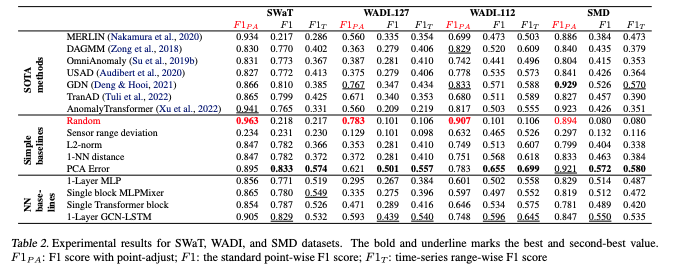
- 所有方法在主要使用的点调整$F1_{PA}$指标上都有更高的分数。
- $F1$和范围方向$F1_T$指标上,简单的基线(如PCA重建误差)在所有数据集上都表现得更好,而其他基线(如1-NN距离和l2 -范数)通常非常接近表现最好的方法。
- nn基线在大多数情况下优于使用这些作为基本构建块构建的更复杂的SOTA深度模型。这是一个强有力的证据,表明与这些简单的基线相比,用于解决TAD任务的复杂解决方案并没有提供任何好处。
四、总结
- 正如我们已经证明的那样,大量用于解决TAD任务的深度学习方法被简单的神经网络和线性基线所打败。此外,当将其中一些方法提炼成线性模型时,它们的性能几乎保持不变。
- 近期几乎基于深度学习的方法都使用了点调整后处理步骤,但往往没有明确说明这一点。另一个常见的错误做法是在表格中使用不匹配的评估指标,即应用pointadjust 并直接将其结果与其他未使用 pointadjust 的方法进行比较。
- 除了暴露这些方法的局限性之外,我们还提供了一套全面的简单基准,可以帮助在坚实的基线上重新开始TAD的研究。