DeepSeek-R1:通过强化学习提升LLM的推理能力
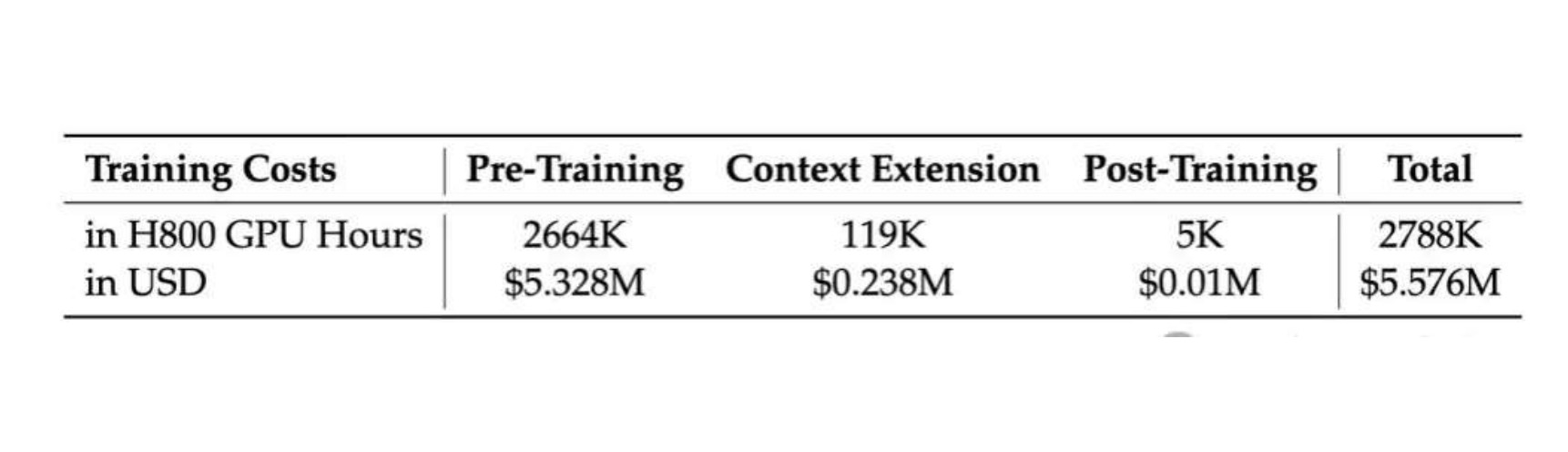
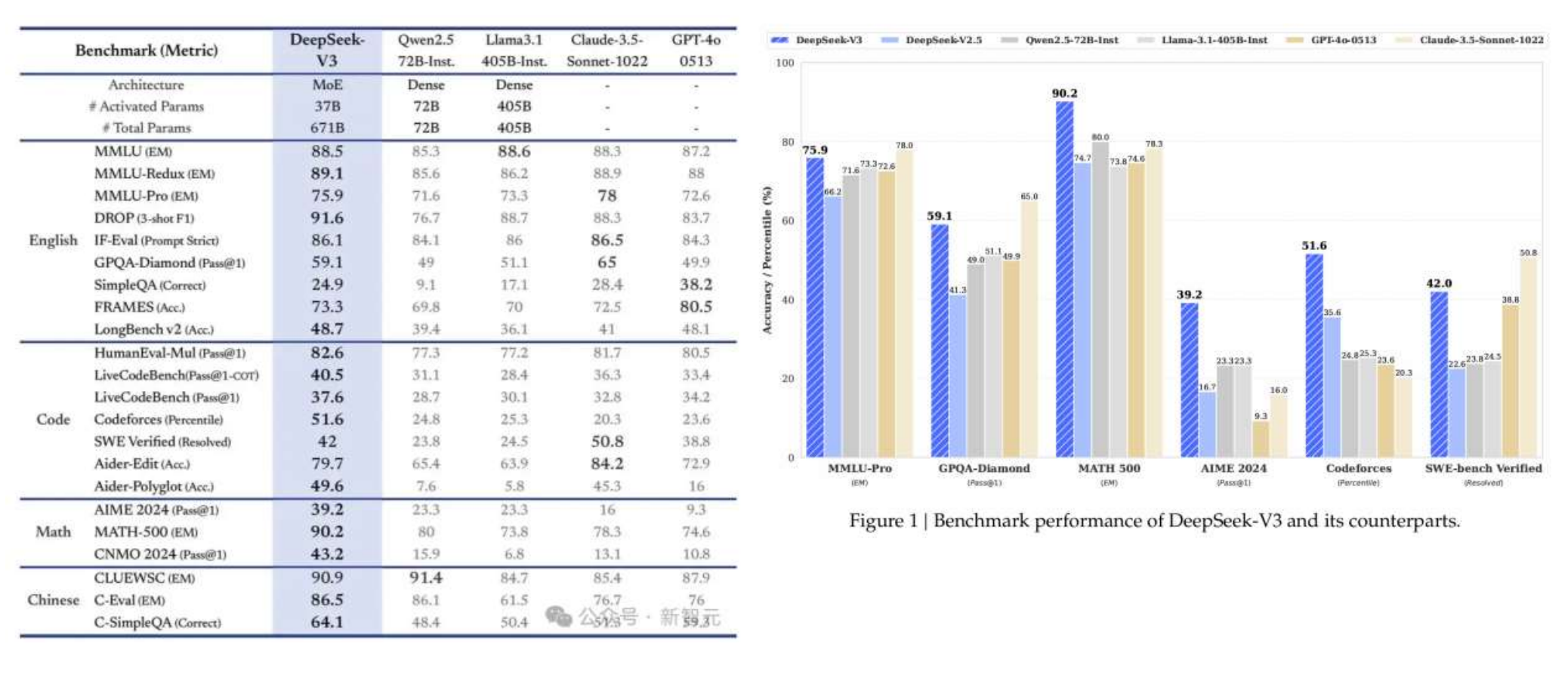
DeepSeek-V3的横空出世引起了轰动,当o1、Claude、Gemini和Llama 3等模型还在为数亿美元的训练成本苦恼时,DeepSeek-V3用557.6万美元的预算,在2048个H800 GPU集群上仅花费3.7天/万亿tokens的训练时间,就达到了足以与它们比肩的性能。DeepSeek-V3 是一个 MoE(Mixture-of-Experts)语言模型,总参数量 671B,每个 Token 激活的参数量为 37B。为实现高效训练与推理,DeepSeek-V3 延续了 DeepSeek-V2 的 MLA(Multi-head Latent Attention)及 DeepSeekMoE 架构。此外,DeepSeek-V3 首创了无需辅助损失的负载均衡策略,还使用了多 Token 预测训练目标以增强性能。