DataFrame-数据检查
Published:
导入pandas库,为了方便起见也导入numpy库

Published:
导入pandas库,为了方便起见也导入numpy库
titanic数据集的目标是根据乘客信息预测他们在Titanic号撞击冰山沉没后能否生存
cifar2数据集为cifar10数据集的子集,只包括前两种类别airplane和automobile
imdb数据集的目标是根据电影评论的文本内容预测评论的情感标签。
2020年发生的新冠肺炎疫情灾难给各国人民的生活造成了诸多方面的影响
Pytorch的基本数据结构是张量Tensor。张量即多维数组。Pytorch的张量和numpy中的array很类似
神经网络通常依赖反向传播求梯度来更新网络参数,求梯度过程通常是一件非常复杂而容易出错的事情。
本节我们将介绍 Pytorch的动态计算图
下面的范例使用Pytorch的低阶API实现线性回归模型和DNN二分类模型
Pytorch的中阶API主要包括各种模型层,损失函数,优化器,数据管道等等
Pytorch没有官方的高阶API,一般需要用户自己实现训练循环、验证循环、和预测循环
张量结构操作主要包括:张量创建,索引切片,维度变换,合并分割
张量数学运算主要有:标量运算,向量运算,矩阵运算,以及 使用非常强大而灵活的爱因斯坦求和函数torch.einsum进行任意维的张量运算
利用这些张量的API我们可以构建出神经网络相关的组件(如激活函数,模型层,损失函数
Pytorch通常使用Dataset和DataLoader这两个工具类来构建数据管道
torch.nn中内置了非常丰富的各种模型层。它们都属于nn.Module的子类,具备参数管理功能
一般来说,监督学习的目标函数由损失函数和正则化项组成。(Objective = Loss + Regularization)
TensorBoard正是这样一个神奇的炼丹可视化辅助工具。它原是TensorFlow的小弟,但它也能够很好地和Pytorch进行配合。甚至在Pytorch中使用TensorBoard比TensorFlow中使用TensorBoard还要来的更加简单和自然
1,继承nn.Module基类构建自定义模型
2,使用nn.Sequential按层顺序构建模型
3,继承nn.Module基类构建模型并辅助应用模型容器进行封装(nn.Sequential,nn.ModuleList,nn.ModuleDict)
Pytorch通常需要用户编写自定义训练循环,训练循环的代码风格因人而异
深度学习的训练过程常常非常耗时,一个模型训练几个小时是家常便饭,训练几天也是常有的事情,有时候甚至要训练几十天
Published in Journal 1, 2021
Spark主要用于大数据的计算,而Hadoop以后主要用于大数据的存储(比如HDFS、Hive,HBase等),以及资源调度(Yarn)。 Spark+Hadoop的组合,是未来大数据领域最热门的组合,也是最有前景的组合
Published in Journal 1, 2021
Spark,是一种”One Stack to rule them all”的大数据计算框架,期望使用一个技术堆栈就完美地解决大数据领域的各种计算任务。Apache官方,对Spark的定义就是:通用的大数据快速处理引擎
Published in Journal 1, 2021
Spark除了一站式的特点之外,另外一个最重要的特点,就是基于内存进行计算,从而让它的速度可以达到MapReduce、Hive的数倍甚至数十倍
Published in Journal 1, 2021
Spark,是一种通用的大数据计算框架,I正如传统大数据技术Hadoop的MapReduce、Hive引擎,以及Storm流式实时计算引擎等, Spark包含了大数据领城常见的各种计算框架:比如Spark Core用于离线计算,Spark SQL用于交互式查询,Spark Streaming用于实时流式计算,Spark MILlib用于机器学习,Spark GraphX用于图计算
Published in Journal 1, 2021
spark 提供了大量的算子,开发只需调用相关api进行实现无法关注底层的实现原理 通用的大数据解决方案,相较于以前离线任务采用mapreduce实现,实时任务采用storm实现,目前这些都可以通过spark来实现,降低来开发的成本。同时spark 通过spark SQL降低了用户的学习使用门槛,还提供了机器学习,图计算引擎等
Published in Journal 1, 2021
Spark相较于MapReduce速度快的最主要原因就在于,MapReduce的计算模型太死板,必须是map-reduce模式,有时候即使完成一些诸如过滤之类的操作,也必须经过map-reduce过程,这样就必须经过shuffle过程
Published in Journal 1, 2021
Spark由于是新崛起的技术新秀,因此在大数据领域的完善程度,肯定不如MapReduce,比如基于HBase、Hive作为离线批处理程序的输入输出,Spark就远没有MapReduce来的完善
Published in Journal 1, 2021
Spark SQL实际上并不能完全替代Hive,因为Hive是一种基于HDFS的数据仓库,并且提供了基于SQL模型的,针对存储了大数据的数据仓库,进行分布式交互查询的查询引擎
Published in Journal 1, 2021
spark将每个任务构建成DAG进行计算,内部的计算过程通过弹性式分布式数据集RDD在内存在进行计算,相比于hadoop的mapreduce效率提升了100倍
Published in Journal 1, 2021
spark 提供了大量的算子,开发只需调用相关api进行实现无法关注底层的实现原理
Published:
Transformer是一种仅使用attention机制、encoder-decoder架构的神经网络,最初应用于NLP领域的机器翻译,后逐渐在语音、CV、时间序列分析等多个领域成为主流深度模型。
Published:
近期越来越多的研究将NLP中的注意力机制融入到视觉任务中,注意力除了能后辅助CNN建立长程依赖关系,也有研究指出注意力可以完全取代卷积操作,同样达到SOTA结果。这就引出一个问题:注意力层的操作是否同卷积操作类似呢?
Published:
Transformers 在一些任务中取得了显著的性能,但由于其二次复杂度(相对于输入长度),对于非常长的序列,它们的速度会非常慢。为了解决这一限制,我们将 self-attention 表示为核特征图的线性点积,并利用矩阵乘积的结合性将复杂度从O(N2) 降低到O(N),其中N为序列长度。我们展示了这种公式允许迭代实现,极大地加速了自回归Transformers ,并揭示了它们与循环神经网络的关系。我们的线性Transformers 实现了与普通Transformers 相似的性能,并且在非常长的序列的自回归预测方面快了4000倍。
Published:
LightGBM 由微软提出,主要用于解决 GDBT 在海量数据中遇到的问题,以便其可以更好更快地用于工业实践中
Published:
时间序列中的统计属性经常发生变化,即数据分布随时间而变化。这种时间分布变化是阻碍准确时间序列预测的主要挑战之一。为了解决这个问题,我们提出了一种简单但有效的归一化方法,称为可逆实例归一化(RevIN)。具体来说,RevIN 由两个不同的步骤组成,归一化和非归一化。前者对输入进行归一化以根据均值和方差来固定其分布,而后者将输出返回到原始分布。此外,RevIN 与模型无关,通常适用于各种时间序列预测模型,预测性能有显着提高。如图 1 所示,RevIN 有效地增强了基线的性能。我们广泛的实验结果验证了对各种现实世界数据集的普遍适用性和性能改进。
Published:
本文介绍了离线检测多元时间序列中多个变化点的算法的选择性调研。采用了一种普适而有结构的方法论策略来组织这个广泛的研究领域。具体而言,本综述中考虑的检测算法由三个要素来描述:代价函数、搜索方法和变化点数量的约束。对这些要素进行了描述、评估和讨论。本文还提供了在名为ruptures的Python软件包中实现的主要算法的实例。
Published:
本文提出了一种分层时间序列预测的新方法,该方法无需任何明确的后处理协调即可产生连贯的概率预测。与最先进的方法不同,所提出的方法同时从层次结构中的所有时间序列中学习
Published:
现有的关于表格数据深度学习的文献提出了各种新颖的架构,并在多个数据集上报告了竞争性的结果。然而,这些模型通常没有被适当地相互比较,并且现有的研究通常使用不同的基准和实验协议。因此,对于研究人员和实践者来说,哪个模型表现最佳尚不清楚。
Published:
最近的工作表明,在长期时间序列预测中,简单的线性模型可以优于几种基于Transformer的方法。受此启发,文章提出了一种基于多层感知器(MLP)的编码器-解码器模型,即时间序列密集编码器(TiDE),用于长期时间序列预测,该模型具有线性模型的简单性和速度,同时能够处理协变量和非线性依赖关系。理论上,文章证明了该模型的线性类似物可以在某些假设下实现对线性动力系统(LDS)的近最优错误率。经验上,该方法可以在流行的长期时间序列预测基准上匹配或优于以前的方法,同时比最好的基于Transformer的模型快5-10倍。
Published:
FTTransformer是一个可以用于结构化(tabular)数据的分类和回归任务的模型。 FT 即 Feature Tokenizer的意思,把结构化数据中的离散特征和连续特征都像单词一样编码成一个向量。 从而可以像对text数据那样 应用 Transformer对 Tabular数据进行特征抽取。 值得注意的是,它对Transformer作了一些微妙的改动以适应 Tabular数据。
Published:
该工作提出了一种time series foundation model,名为TimesFM。该工作的关键在于构建了一个时间序列预测数据集,该数据集由Google trends, Wiki Pageviews和合成数据组成。TimesFM的性能上略微优胜llmtime,也优胜了traditional methods。
Published:
这篇是2023年ICLR的文章,提出了一种有效的多元时间序列预测和自监督表示学习模型 PatchTST,主要是基于Transformer做了以下两点改进
Published:
深度学习为时间序列分析的进步做出了巨大贡献。 尽管如此,深度模型在现实世界的数据稀缺场景中仍可能遇到性能瓶颈,而由于当前基准测试中小模型的性能饱和,这种瓶颈可能被隐藏起来。 同时,大型模型通过大规模预训练在这些场景中展现了强大的威力。 随着大型语言模型的出现,取得了持续的进步,表现出前所未有的能力,例如少样本泛化性、可扩展性和任务通用性,而这些能力是小型深度模型所不具备的。 为了从头开始改变训练场景小模型的现状,本文针对大型时间序列模型(LTSM)的早期开发。 在预训练过程中,我们整理了多达 10 亿个时间点的大规模数据集,将异构时间序列统一为单序列序列 (S3) 格式,并开发面向 LTSM 的 GPT 风格架构。 为了满足不同的应用需求,我们将时间序列的预测、插补和异常检测转换为统一的生成任务。
Published:
位置编码最近在Transformer架构中显示出了有效性。在序列中不同位置元素之间的依赖关系建模,它提供有价值的监督。本文首先研究将位置信息集成到基于Transformer语言模型的学习过程。然后,作者提出一种新的方法,称为旋转位置编码(RoPE),可有效地利用位置信息。具体而言,所提出的RoPE用旋转矩阵对绝对位置进行编码,同时在自注意公式中引入显式的相对位置依赖性。值得注意的是,RoPE实现了有价值的特性,如序列长度的灵活性、随相对距离增加而衰减的token间依赖性,以及为线性自注意配备相对位置编码。最后,在各种长文本分类基准数据集上评估了这个旋转位置嵌入的增强Transformer,也称为RoFormer。RoFormer已集成到开源的Huggingface代码库中。
Published:
实践经验发现,穿鞋睡觉的人第二天起床大概率都会头疼,我们可以确定“穿鞋睡觉”和“起床头疼”有正相关性。 那么,“睡觉穿鞋”是否是“起床头疼” 的原因? 相关性是否可以直接等价于因果性?什么情况下相关性=因果性? 因果性如何度量评估?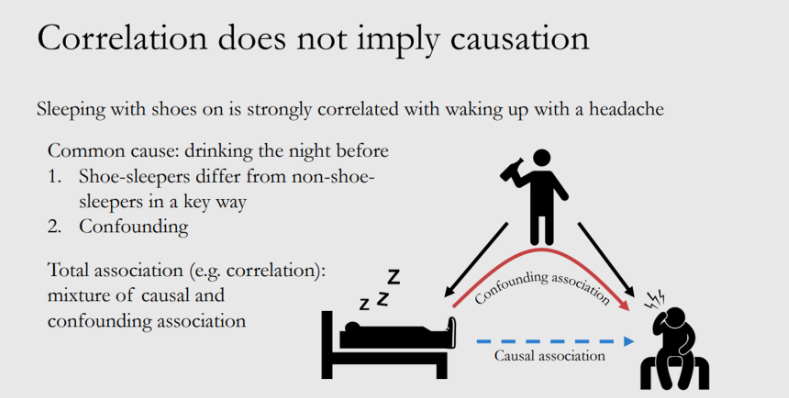
Published:
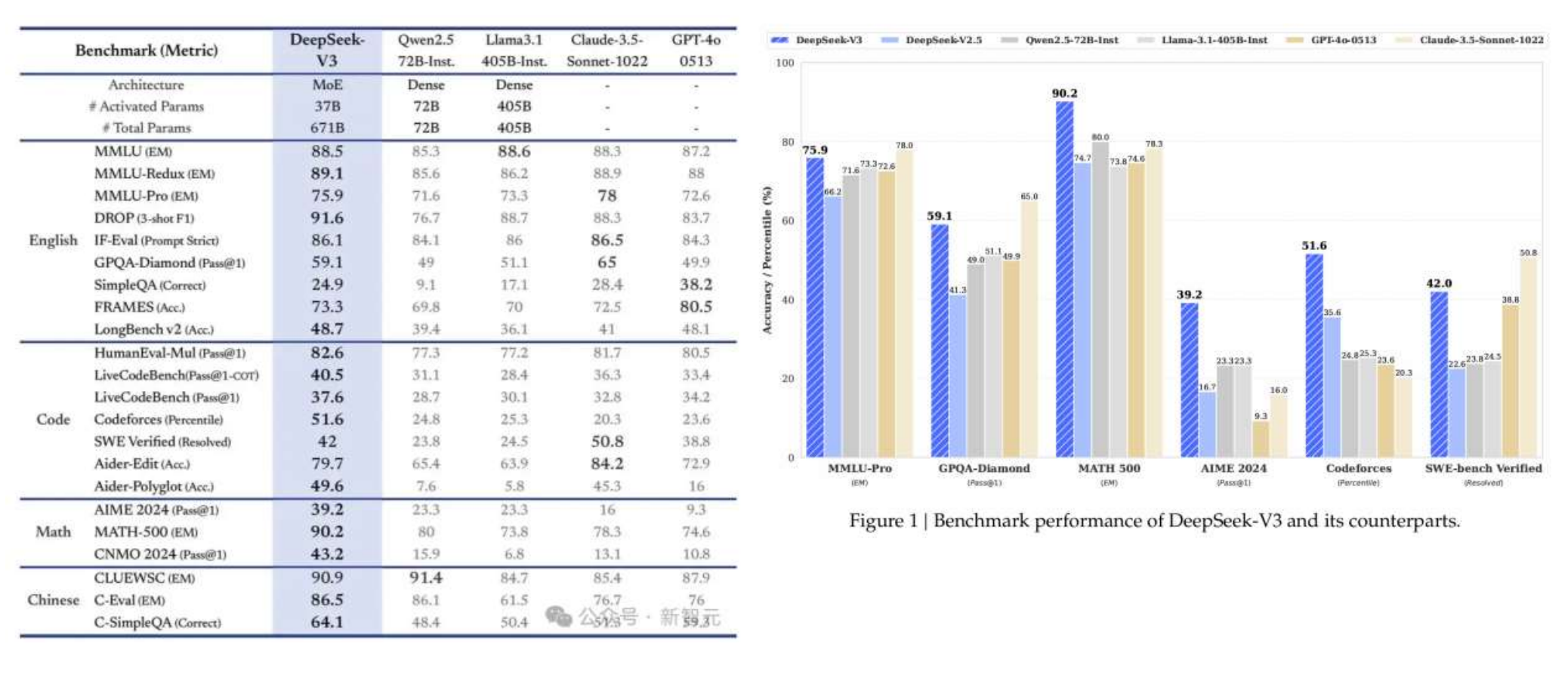
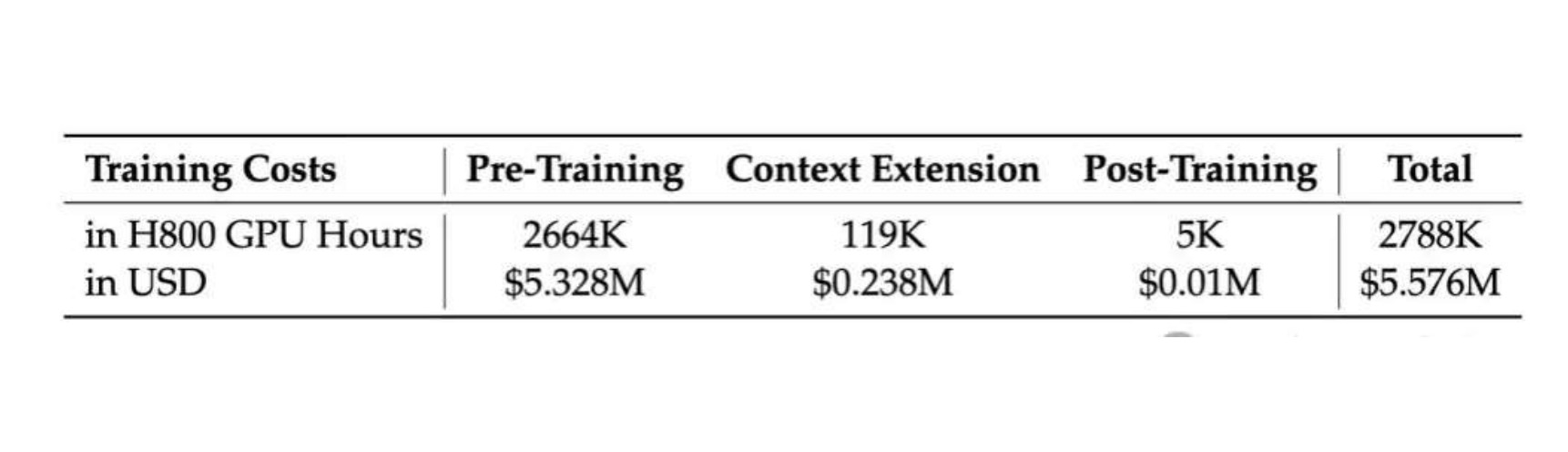
Deepseek系列更看重“成本”与“效率“的平衡。 训练DeepSeek-V3每万亿tokens仅需要180KH800 GPU小时,假设H800 GPU的租赁价格为每GPU小时2美元,总训练成本仅为557.6万美元。 DeepSeek-V3 是一款拥有671B参数的大型混合专家(MoE) 模型,其中每个token 会有37 B参数被激活。 14.8T高质量token上完成了训练。
Published:
在⼈⼯智能领域,⽆监督语⾔模型(Language Models, LMs)的发展已经达到了令⼈惊叹的⽔平,这些模型能够在⼴泛的数据集上进⾏预训练,学习到丰富的世界知识和⼀定的推理能⼒。然⽽,如何精确控制这些模型的⾏为, 使其按照⼈类的偏好和⽬标⾏动,⼀直是⼀个难题。这主要是因为这些模型的训练完全是⽆监督的,它们从⼈类⽣成的数据中学习,⽽这些数据背后的⽬标、优先级和技能⽔平五花⼋⻔。例如,我们希望⼈⼯智能编程助⼿能够理解常⻅的编程错误以便纠正它们,但在⽣成代码时,我们⼜希望模型能偏向于它训练数据中的⾼质量编码能⼒,即使这种能⼒可能相对罕⻅。
Published:
微调大型语言模型(LLMs)是提高性能和调整行为的有效方法。然而,对于非常大的模型来说,微调成本非常高昂,需要大量的GPU内存。传统的量化方法虽然可以减小模型的内存占用,但只适用于推理阶段,无法在训练过程中有效减少内存需求,这对于大型模型的微调构成了严重的限制。因此,当前研究面临着在保持性能的同时降低微调过程中的内存需求的挑战。
Published:
近年来,Transformer在自然语言以及计算机视觉领域取得了长足的发展,逐渐成为深度学习的基础模型。在时序分析领域,受益于其强大的序列建模能力与可扩展性,Transformer广泛应用于时序预测,派生出了许多模型改进。
Published:
Transformers 在一些任务中取得了显著的性能,但由于其二次复杂度(相对于输入长度),对于非常长的序列,它们的速度会非常慢。为了解决这一限制,我们将 self-attention 表示为核特征图的线性点积,并利用矩阵乘积的结合性将复杂度从O(N2) 降低到O(N),其中N为序列长度。我们展示了这种公式允许迭代实现,极大地加速了自回归Transformers ,并揭示了它们与循环神经网络的关系。我们的线性Transformers 实现了与普通Transformers 相似的性能,并且在非常长的序列的自回归预测方面快了4000倍。
Published:
提升树是一种高效且被广泛使用的机器学习方法。在本文中,我们描述了一个可扩展的端对端的提升树系统,叫做XGBoost,该系统被数据科学家广泛使用,在许多机器学习任务中取得了显著效果。针对稀疏数据,我们提出一种新的稀疏数据感知算法。我们也提出了分布式加权分位数草图来近似实现树模型的学习。更重要的是,我们陈述了缓存访问模式、数据压缩和分片的见解以构建可扩展的提升树系统。通过结合这些知识,XGBoost可以使用比现有系统少得多的资源就能够扩展数十亿的实例。
Published:
DeepSeek-V3的横空出世引起了轰动,当o1、Claude、Gemini和Llama 3等模型还在为数亿美元的训练成本苦恼时,DeepSeek-V3用557.6万美元的预算,在2048个H800 GPU集群上仅花费3.7天/万亿tokens的训练时间,就达到了足以与它们比肩的性能。DeepSeek-V3 是一个 MoE(Mixture-of-Experts)语言模型,总参数量 671B,每个 Token 激活的参数量为 37B。为实现高效训练与推理,DeepSeek-V3 延续了 DeepSeek-V2 的 MLA(Multi-head Latent Attention)及 DeepSeekMoE 架构。此外,DeepSeek-V3 首创了无需辅助损失的负载均衡策略,还使用了多 Token 预测训练目标以增强性能。
箱型推荐, 上海市, 2020
使用装箱算法进行包材推荐,通过运算为员工提供打包方案,指导员工挑选合适的包材为每个订单打包,大大降低了员工挑错包材或者挑选太大的包材的可能性,极大地降低了包材成本,快递成本,客诉成本,提升了打包作业的效率,减少包材使用也有利于环境保护。
时间序列预测, 上海市, 2022
销售预测作为供应链领域的核心算法,目前已经服务于国内数百家门店,日补货数百万SKU,为提升人力效率、减少缺货损耗发挥了重要作用。本文将揭示盒马销量预测的整体框架介绍和技术演进过程。
Xgboost专栏, 上海市, 2023
XGBoost是一个优化的分布式梯度增强库,旨在实现高效,灵活和便携。 它在 Gradient Boosting 框架下实现机器学习算法。XGBoost提供并行树提升(也称为GBDT,GBM),可以快速准确地解决许多数据科学问题。相同的代码在主要的分布式环境(Hadoop,SGE,MPI)上运行,并且可以解决数十亿个示例之外的问题。XGBoost [2]是对梯度提升算法的改进,求解损失函数极值时使用了牛顿法,将损失函数泰勒展开到二阶,另外损失函数中加入了正则化项。
Xgboost专题, 上海市, 2023
XGBoost 最初是由 Tianqi Chen 作为分布式(深度)机器学习社区(DMLC)组的一部分的一个研究项目开始的。XGBoost后来成为了Kaggle竞赛传奇——在2015年的時候29个Kaggle冠军队伍中有17队在他们的解决方案中使用了XGboost。
Xgboost专题, 上海市, 2023
XGBoost是陈天奇等人开发的一个开源机器学习项目,高效地实现了GBDT算法并进行了算法和工程上的许多改进,被广泛应用在Kaggle竞赛及其他许多机器学习竞赛中并取得了不错的成绩。
优化, 上海市, 2023
基于订单大数据,计算出最合适的箱型和长宽高,从而优化纸箱型号、减少包材浪费;根据订单的物件体积、重量以及特性,推荐最合适的箱型和装箱方案。如此一来,大小合适的箱子不仅可以减少商品与箱子之间的碰撞、减少耗材成本,还节省了运输成本、运输空间,同时也更加绿色环保,减少过度包装,一举多得;不断推动物流数字化、智能化、绿色化。
Xgboost专题, 上海市, 2023
XGBoost 最初是由 Tianqi Chen 作为分布式(深度)机器学习社区(DMLC)组的一部分的一个研究项目开始的。XGBoost后来成为了Kaggle竞赛传奇——在2015年的時候29个Kaggle冠军队伍中有17队在他们的解决方案中使用了XGboost。
优化, 上海市, 2023
供应链存在的主要问题是牛鞭效应非常严重。牛鞭效应是指上游的一些波动经过层层传导,到下游会逐级放大,波动越到后端的需求侧的变化幅度会越大。因此,对于供应链预测,我们所要面对的一个问题就是如何最大限度地减小需求波动对这些决策质量的影响。如果能做到这一点,其实就决定了整个供应链的成本、效率和服务水平。 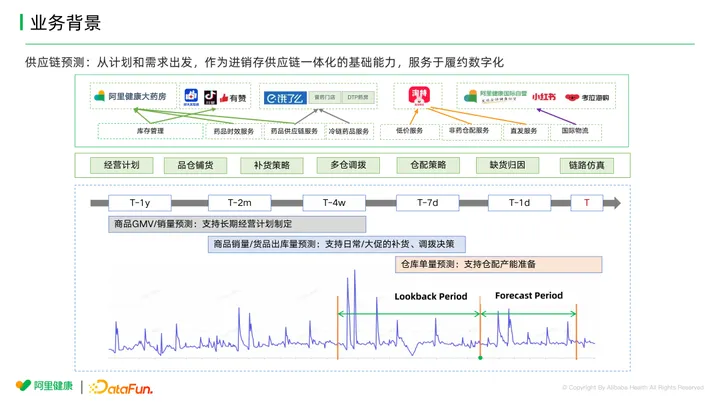
Xgboost专栏, 上海市, 2024
XGBoost(eXtreme Gradient Boosting)是一个高效的机器学习库,也是一种基于梯度提升决策树(Gradient Boosting Decision Tree)的集成学习算法,专为提升树算法的性能和速度而设计。它实现了梯度提升框架,并支持回归、分类及排序的问题。XGBoost通过优化计算资源使用和提供高度可配置的参数,成为数据科学竞赛和实际应用中的热门选择。 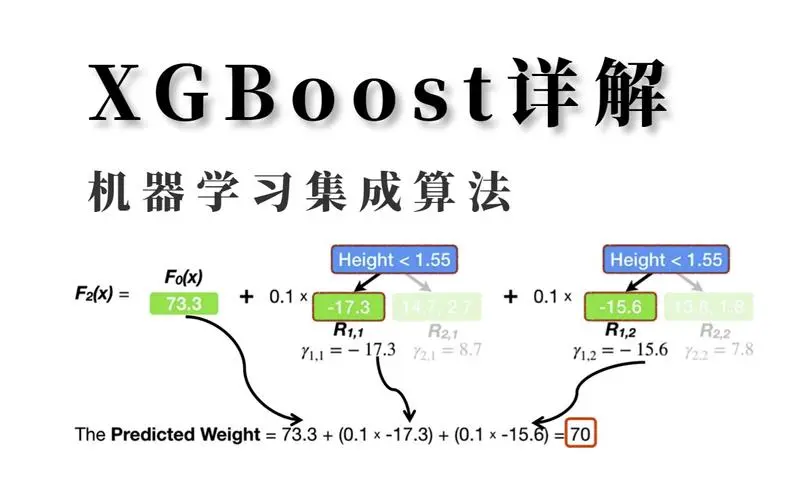
lightGBM专栏, 上海市, 2024
LightGBM是微软于2016年开发的梯度提升决策树模型(GBDT),与其他GBDT模型相比,LightGBM的最大特点是训练效率更快、准确率更高。
lightGBM专栏, 上海市, 2024
Light GBM 代表轻量级梯度提升机,因此,它是另一种使用基于树的学习的梯度提升算法,由微软开发: 与任何其他梯度提升算法一样,它主要用 C++ 实现。此外,它还可以与许多其他扩展(Python、R、Java 等)交互。 由于某些独特的特点,它与其他梯度提升算法区别开来。
Xgboost专栏, 上海市, 2024
本文不讲如何使用 XGBoost 也不讲如何调参,主要会讲一下作为 GBDT 中的一种,XGBoost 的原理与相关公式推导。为了循序渐进的理解,读者可先从简单的回归树再到提升树再来看本文。我们现在直接从 XGBoost 的目标函数讲起。
lightGBM专栏, 上海市, 2024
LightGBM在Higgs数据集上LightGBM比XGBoost快将近10倍,内存占用率大约为XGBoost的1/6,并且准确率也有提升。GBDT在每一次迭代的时候,都需要遍历整个训练数据多次。如果把整个训练数据装进内存则会限制训练数据的大小;如果不装进内存,反复地读写训练数据又会消耗非常大的时间。尤其面对工业级海量的数据,普通的GBDT算法是不能满足其需求的。
lightGBM专栏, 上海市, 2024
同XGBoost类似,LightGBM依然是在GBDT算法框架下的一种改进实现,是一种基于决策树算法的快速、分布式、高性能的GBDT框架,主要说解决的痛点是面对高维度大数据时提高GBDT框架算法的效率和可扩展性。
大模型-专栏, 上海市, 2026
MOE(Mixture of Experts,混合专家模型) 是一种神经网络架构设计范式,其核心思想是:将大型神经网络分解为多个相对独立的”专家”子网络,并通过门控机制(Gating Mechanism)动态选择激活部分专家来处理特定输入。